Why We Lose Sleep Some Nights
Is the end of the world uncomfortably close?

|
|
src |
Derek de Solla Price created scientometrics, which is “the science of measuring and analyzing science.” You can tell you’re a natural theoretician if you instantly think, what happens when scientometrics is applied to itself? But there is no paradox of self-reference here, because scientometrics per se is applied to the science of the past, to papers that have already been published. Yet we who are doing science have to look ahead to impact on the future, and that involves unpublished possibilities.
Today Ken and I want to discuss what keeps us worried sometimes.
David Hilbert once said:
One can measure the importance of a scientific work by the number of earlier publications rendered superfluous by it.
Our worry looking ahead is based exactly on this quotation. Some conjectures are what we will call “normal” and others are “abnormal.” A normal conjecture is one whose truth does not wipe out previous developments. For example, in our opinion Andrew Wiles’ two papers proving Fermat’s Last Theorem, one joint with Richard Taylor, did not diminish most previous work—indeed they built on it. A grand conjecture like the Langlands Program would validate our understanding of algebra and lash previous work together into a new foundation. But abnormal results do more than overshadow past work.
P and NP: Equal or Not Equal?
Right now the P versus NP page lists one dozen claimed proofs of 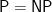
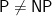
Many of our colleagues believe that a proof of 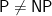
I (Dick) believe that 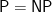
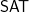
Jin-Yi Cai, who has been a faculty colleague of both Ken and myself, is visiting Buffalo this weekend, and gives permission to relay his main reason for believing 
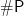


Normal Conjectures
Right now in mathematics there is the potential proof solving one of the great open problems of number theory. This is the ABC Conjecture which we discussed here. Besides the length and complexity of this proof whether correct or not it appears to have substantial new mathematics. The biggest surprise with this new proof is that while many have believed all along that the ABC Conjecture is true, no one seemed to have any approach at all. Of course the proof could be wrong, could have a bug, yet it may also be correct. We will see.
The Riemann Hypothesis is a long-standing conjecture with deep impact. Although we may expect that a proof would carry foundational new insights, the fact of its truth would ratify beliefs we are already building on. The falseness of Riemann [in any of various forms] would certainly wipe out many papers with theorems that begin “Assuming the [extended] Riemann Hypothesis…”—as Lance Fortnow just now listed among “Things a Complexity Theorist Should Do At Least Once.”
However, Riemann can be viewed as part of a spectrum of assertions about the distribution of primes and the behavior of the Möbius function. Cramér’s conjecture, as we discussed here, makes a much stronger assertion about gaps between primes than what follows directly from Riemann, 

There is a difference between “normal” conjectures like the ABC Conjecture and our own
Abnormal Conjectures
To see why
Imagine, if you can, that someone proves the unexpected: they prove
Much of CS theory would disappear. In my own research some of Ken’s and my “best” results would survive, but many would be destroyed. The Karp-Lipton Theorem is gone in this world. Ditto all “dichotomy” results between 

I am currently teaching Complexity Theory at Tech using the textbook by Sanjeev Arora and Boaz Barak, while Ken is using the new edition of the text by Steve Homer and Alan Selman, supplemented by his CRC Handbook chapters with Eric Allender and Michael Loui. Most of the 573 pages of Arora-Barak would be gone:
-
Delete all of chapter 3 on
- Delete all of chapter 5 on the polynomial hierarchy.
- Delete most of chapter 6 on circuits.
- Delete all of chapter 7 on probabilistic computation.
- Mark as dangerous chapter 9 on cryptography.
- Delete most of chapter 10 on quantum computation—who would care about Shor’s algorithm then?
- Delete all of chapter 11 on the PCP theorem.
I will stop here. Most of the initial part of the book is gone. The same for much of Homer-Selman, and basically all of the “Reducibility and Completensss” CRC chapter.
Open Problems
Is the wanton conceptual destruction wrought by 
Would it be a true apocalypse, or would we move to talking about “nearly-linear” versus “quadratic-plus” time, starting (say) with Merkle’s Puzzles?
[updated paragraph on Jin-Yi’s work]


Very nice and interesting post. Many thans especially to draw the attention to Jin-Yi’s work, I did not know it so far.
Probably it would be more precise to write FP = sharp-P instead of P = sharp-P
It would be an interesting world if P was NP but FP was a real subset of sharp-P. There are some easy decision problems, for example, deciding if a directed graph contains a cycle, whose corresponding counting problem in sharp-P essentially cannot be approximated, enven in a stochastic way unless RP = P. So if P = NP but FP was not sharp-P, then these problems became interesting again, as there would be a hope to find an FPRAS algorithm for them.
If FP was sharp-P, that would be an Armageddon, all the nice work on rapidly mixing Markov chains could be forgotten.
The eventuality that is undecidable also has points of interest. One might conclude “We might as well assume
is undecidable also has points of interest. One might conclude “We might as well assume 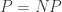 , on the practical grounds that no one will ever prove us wrong.” But this would be incorrect: the standard definitions of complexity theory are compatible with the existence of
, on the practical grounds that no one will ever prove us wrong.” But this would be incorrect: the standard definitions of complexity theory are compatible with the existence of  algorithms, that are
algorithms, that are  -complete, but not provably
-complete, but not provably  -complete.
-complete.
In a practical sense, this outcome is completely familiar and acceptable … we commonly use algorithms whose correctness we cannot prove and/or whose runtimes we cannot predict. So in this sense the “standard” definition of the languages in complexity class accord with the common practice that we do not require proofs that the TMs that decide
accord with the common practice that we do not require proofs that the TMs that decide  provably have polynomial runtimes … it suffices for us to have faith (that originates in oracles and/or experience).
provably have polynomial runtimes … it suffices for us to have faith (that originates in oracles and/or experience).
On the other hand, it is natural to be uncomfortable with the notion that may include languages that are efficiently recognized solely by cryptic algorithms, and to wonder whether
may include languages that are efficiently recognized solely by cryptic algorithms, and to wonder whether  ought to be restricted to the complementary set of gnostic languages — per the definitions on the TCS cryptic/gnostic wiki — and to wonder in particular whether a proof of
ought to be restricted to the complementary set of gnostic languages — per the definitions on the TCS cryptic/gnostic wiki — and to wonder in particular whether a proof of  might be feasible, on the grounds that for practical complexity-theoretic purposes, such a proof would be comparably useful as a proof of
might be feasible, on the grounds that for practical complexity-theoretic purposes, such a proof would be comparably useful as a proof of  .
.
Conclusion Far from being an apocalypse for complexity theory, a provable cryptic/gnostic dichotomy would “immanentize the eschaton” (Google it!). 🙂
can’t let “immanentize the eschaton” go-by without comment! Voegelin had a habit of using terms that he just expected people to grasp, but they are no doubt rich in context. A different image might help. His sense of bringing forth order out of disorder involves an understanding about symbols as tools; like a lens can focus attention on reality. Some people achieve insight by using, and often creating, symbols, in this way, but many who follow subsequently turn their attention to the lens itself (making it immanent) which causes the lens to become clouded and no longer useful as a way for the subject to live now that it has become an object for the subject to worship.
Dear Dick and Ken,
Thanks for this discussion, and mentioning my ideas on why I believe at least
FP \not = #P. If I may, let me elaborate a little. In a number of recent dichotomy
theorems for counting type problems, we repeatedly found the following situation.
Some reduction proofs showing #P-hardness were able to give sweeping proofs
for a huge swath of the problem universe. The reasoning that such proofs work
usually depend on pretty complicated arguments, such as the solutions
of algebraic equations, or involving eigenvalues and eigenvectors. However these
reduction specifically avoids (or fails) for some isolated places, where it turns out
the problem is solvable in P exactly at those places. These P-time algorithms
sometimes were known (such as the FKT algorithm, or holographic
transformations of such algorithms), sometimes they were unknown, and only
after repeated attempts to find a reduction that “just” happens to fail, we manage
to find an algorithm for these “exceptional” problems. The serendipity seems just
a little too accidental if P were equal to #P. After all, how would these reductions
“know” such algorithms, and specifically avoid these problems?
This phenomenon was observed repeatedly, for example
in http://arxiv.org/abs/1008.0683, with Pinyan Lu and Mingji Xia
the “clever” hidden algorithm is the FKT. (an algebraic system was found to
miss a solution exactly where the parameter setting corresponds to the planar
perfect matching problem; the existence of a solution to the algebraic system
gives #P-hardness.)
Also in http://arxiv.org/abs/0903.4728 with Xi Chen and Pinyan Lu
there were also many instances, such as Gauss sum.
Jin-Yi
> and only
> after repeated attempts to find a reduction that “just” happens to fail, we manage
> to find an algorithm for these “exceptional” problems.
Have you tried equally hard to find P algorithms for odd areas where the #P-complete reduction *did* work?
Are you working on showing that holographic algorithms are insufficient for the #P-complete cases? (Or at least, given some ways of modelling the problem, as was shown for #3SAT)
Hello Simon,
>Have you tried equally hard to find P algorithms for odd areas where the >#P-complete reduction *did* work?
Can’t say we did. (Since I believe P \not = #P, it does not seem to
be a very promising pursuit…) But given that a dichotomy is proved,
“all one needs to do” is to find a P algorithm for *any one* problem
in the class not already known to be in P. (But again, given my
belief, honestly I should not encourage people to try that.)
But I am not sure why you call those problems where
#P-hardness reduction worked, “odd areas”.
One of the cardinal rules we learned from all this work on counting
problems is this: In order to be polynomial time computable, there
has to be *fantastic* mathematical structures to the constraint functions
(such as being definable by quadratic forms, and possessing certain
group structures etc). All the rest are #P-hard. So you may call them
“odd”, but I think of them as simply most everything else.
> But I am not sure why you call those problems where
#P-hardness reduction worked, “odd areas”.
I meant areas where perhaps reduction was a little more complicated than others, not that it was odd in general.
I certainly don’t believe that FP=#P (I would call myself uncertain), but it seems that given the novelty of holographic algorithms as a means of constructing algorithms, we should at least have a reasonable try at using them on the hard cases, “just in case”. At least with as much effort as it took to find the known P algorithms!
I enjoyed your Domain Size 3 paper (though I have yet to work through all the details!). Do you think now that a dimensional collapse will work for all domain sizes? What’s the next big task you intend to tackle with/about holographic algorithms?
Hello Simon,
Your point that, “just in case”…we should “have a reasonable try” for a P time algorithm for those problems, certainly cannot be refuted logically at present time. Les Valiant did say, “any proof of P \not = NP may need to explain, and not only to imply, the unsolvability” of NP-hard problems using holographic algorithms.
Re the “Domain Size 3 paper” I suppose you are referring to
http://arxiv.org/abs/1207.2354
I am glad that you find it enjoyable. Pl feel free to ask any questions.
To your two questions, let me offer these explanations:
1. There are at least two types of holographic algorithms, those work over planar graphs (introduced by Valiant, using matchgates), and those work over general (non-planar) graphs (such as Fibonacci gates).
2. The “Domain Size 3 paper” is for the second kind. We don’t have a similar result for the planar type.
3. We currently have a basis collapse theorem for domain size up to 4 (unpublished), for matchgates based type holographic algorithms. The proof is just being written up, and is pretty technical. The main ingredients are the Matchgate Identities, and the group property of matchgate signatures.
Beyond domain size 4, we don’t have any result.
I consider the following are major open areas:
Higher domain (i.e. variables are not restricted to Boolean) Holant problems.
Note that our “Domain Size 3 paper” is only about one ternary symmetric
function in the Holant^* framework. It barely scratched the surface.
The matchgate theory for higher domain problems over planar problems. This applies to both Graph homomorphisms and #CSP, in addition to Holant problems.
Jin-Yi
Thank you for the reply Jin-Yi! I’m sure I will have more questions over time.
What dimension does your new matchgate basis collapse theorem collapse to? Or should I wait and see? 🙂
>What dimension does your new matchgate basis collapse theorem collapse to?
To dimension at most 4. A natural conjecture is, for arbitrary domain size n, there should be a matchgate basis collapse theorem to dimension at most the largest power of 2 less than or equal to n.
> To dimension at most 4. A natural conjecture is, for arbitrary domain size n, there should be a matchgate basis collapse theorem to dimension at most the largest power of 2 less than or equal to n.
Interesting. So n=3 -> dim=2? I would have guessed it rounded up (went to the smallest power of 2 greater than or equal to n, so n=3 needing dim=4).
It seems like many people who claim to believe that in their actions support the opposite.
in their actions support the opposite.  says that the best way to solve the problem is to guess and then test, whereas the whole current science approach requires steady small improvement, resembling convex programming approach. My conclusion those people in the depth believe
says that the best way to solve the problem is to guess and then test, whereas the whole current science approach requires steady small improvement, resembling convex programming approach. My conclusion those people in the depth believe  ! In contrast, say, trisectors take the opposite approach, and try to guess the right algorithm. Looks like duality 😉
! In contrast, say, trisectors take the opposite approach, and try to guess the right algorithm. Looks like duality 😉
Here is the crazy (crackpot) idea to test. The main problem in the NP problems is the exponentially large search space. What is interesting it is easy to create exponentially many distinct points with the small set of quadratic equations. For instance, defines
defines  points in
points in  , which is easy to find. If we add additional, even linear, constraint, like
, which is easy to find. If we add additional, even linear, constraint, like  the problem of finding common solution, or variety, becomes NP-hard. In this particular case it encodes the partition problem.
the problem of finding common solution, or variety, becomes NP-hard. In this particular case it encodes the partition problem.
Current approaches, as I understands them are trying to apply linear methods to solve the problem, that goes to Groebner basis, border basis, companion matrices, and Nullstellensatz. In any approach, to give the certificate of empty variety, or that the system have no common solution one need, at least implicitly test all exponentially many points. The linear methods can do it only one per equation. On the other hand, the above example show that it is not hard to recognize exponentially many points with few equations. Therefore, one need to use quadratic forms to simplify (complicate) the life.
The crackpot algorithm for partition problem.
Input: vector
Output: Who knows.
Local variables:
A vector of quadratic expressions (componentwise)
Linear equation
Step 1. Elimination of linear equation.
We build binary tree as in heap sort, and start with the bottom of the tree.
Recursion step. in the linear equation.
in the linear equation. lead to
lead to  . There are corresponding changes in the quadratic equations. In particular, the only pair of variables
. There are corresponding changes in the quadratic equations. In particular, the only pair of variables  in corresponding quadratic equations are mixed. Repeat with upper level of the binary tree, until the top of the tree is reached.
in corresponding quadratic equations are mixed. Repeat with upper level of the binary tree, until the top of the tree is reached.
For each pair of nodes we have the terms
We are going to rotate the system of coordinates in a way only one term will survive, e.g.
At the top of the tree only one variable is left that have to be zero. Substitute it to the quadratic equations. If no partition exists the set of remaining quadratic equations is inconsistent. The particular quadratic equation consists only of the variables represented by the nodes connecting bottom of the tree with the top of the tree and their siblings. We are going to use this property to remove variables. Recall that we have equations in
equations in  variables.
variables.
Step 2. Eliminating variables.
Start with the bottom of the tree.
Recursion step. Each sibling nodes represent 2 quadratic equations with the same set of variables. There are 2 of them, and they are symmetric. Therefore, they simultaneously diagonalizable, e.g there is linear change of variables that lead to the following form . Thus, we can remove one variable corresponding to right sibling. Translate the quadratic equation without the right sibling to the upper level of the tree. If equations are linearly dependent translate one of them to the upper level of the tree. Repeat to the top of the tree.
. Thus, we can remove one variable corresponding to right sibling. Translate the quadratic equation without the right sibling to the upper level of the tree. If equations are linearly dependent translate one of them to the upper level of the tree. Repeat to the top of the tree.
Step 3. Analysis of resulting equation. – The system is inconsistent.
– The system is inconsistent. . We need to back substitute this equation to check the consistency, or may be not.
. We need to back substitute this equation to check the consistency, or may be not.
Case 1. equation reads
Case 2. there is more than one variable – report bug in the program. That case imply there are infinitely many solutions, which contradicts the construction of the initial system of equations.
Case 3.
Thanks for correcting typo in Nullstellensatz. The initial construction of binary tree seems to be not clear. All the variables are attached to the bottom of the tree – there are n nodes at the bottom of the tree. The next level consists only of nodes corresponding to every second variable, etc recursively. e.g. node corresponding to appears in every level,
appears in every level,  in every layer except the top one.
in every layer except the top one.
Something you can’t feel by any of your senses behaves as if it didn’t exist. Thus, P=NP is the blind spot of computer science. It’s another thing than classical undecidability, even though it has similar properties. Therefore there’s absolutely no harm in assuming P!=NP: the practical consequences are exactly the same. To some extent, the distinction’s almost meaningless…
And yet somebody [more than] believes [F]P == #P.
Assume that prof. A knows that P equals NP because his friend prof. X told him about a simple proof of it. However, prof. A acts like he doesn’t know this fact and ends up receiving a 1-2 million dollar NSF grant for several years to do “RESEARCH” on several problems that are complete for the kth level of the polynomial hierarchy and jth level of the counting hierarchy.
Assume that prof. B knows that P equals NP because his friend prof. Y told him about a simple proof of it. However, prof. B acts like he doesn’t know this fact and ends up writing a “TEXT BOOK” on computational complexity and gets promoted and tenured.
Assume that prof. C knows that P equals NP because he himself came up with the simple proof of it. Then he goes around betting LOTS of money on attempted proofs of P does not equal NP.
And the list goes on…. So now are we loosing sleep because somebody came up with this proof by themselves and they are trying to publish it? We did not loose sleep when we got those grants, wrote those text books, taught false material, got tenured and jerk around people?
Anyways, Donald Knuth was right when he said at the Turing event that he thinks we got the wrong definition of NP. He said NP should have been defined as problems where there exists a polynomial time algorithm but it is nearly impossible for us to find it. You can check the webcast for the exact quote.
Actually, it is not just NP that was defined wrong. There are several complexity classes, especially the probabilistic classes, that were totally defined wrong and anyone with some common sense could see it.
Sometimes I think that the definition of FPRAS is too strict, I would imagine a complexity class where both a certain level of relative and absolute error is tolerated. If we call this class LR-FPRAS (less restricted FPRAS), I cannot see why an LR-FPRAS could not exist for some counting problem whose corresponding decision problem is NP-complete. For FPRAS we know if FPRAS exists for such a counting problem then NP was RP, in which we do not believe. The proof for it is that due to the small relative error, we could decide with high probability whether or not a solution exists, since 1 minus a small relative error will be bigger than 0.5, similarly 0 + a small relative error is still 0 which is smaller than 0.5. But if we tolerated some absolute error, then we could not separate 0 and bigger than 0.
“You can check the webcast for the exact quote.”
Anyone have a URL for this? I haven’t been able to find a webcast yet …
Paul.
Do you really believe in a conspiracy theory concerning P=NP? You know, a proof of this statement couldn’t be as “simple” as that of prof. C… On the contrary, the reason nobody’s found it yet is because it’s too complex!
“Snitch” and Paul Homer, an invaluable on-line resource in which Don Knuth (and colleagues) discusses these issues is the webcast of the ACM A.M. Turing Centenary Celebration, specifically the panel discussion “An Algorithmic View of the Universe“ (this discussion is selectable, from among many excellent Turing Centenary lectures and panel discussions, via the menu at-right on ACM web page).
It would be hard to conceive a better Algorithms panel than this: Chair: Christos Papadimitriou; Panel: Leonard Adleman, Richard Karp, Donald Knuth, Robert Tarjan, Leslie Valiant. 🙂
In particular, the closing statement by Richard Karp, remarking upon the astounding efficiency of heuristic algorithms for solving problems that are (formally) NP-complete, comes closest to addressing Snitch’s issues.
Moreover, the opening assertion by Leslie Valiant that “Unexamined life does not exist” — if we interpret “examine” in its strictly physical and thus mathematically Lindbladian sense — vividly illuminates the gist of the Kalai/Harrow debate.
In-between Valiant and Karp, we hear Adleman, Karp, Knuth, Tarjan, and Papadimitriou, voicing their personal opinions regarding a spectrum of complexity-theoretic issues that will be familiar to all readers of Gödel’s Lost Letter and P=NP.
Highly recommended … and perhaps too, the Knuth quote that Paul Homer requested is to be found elsewhere on this outstanding ACM Turing Centenary website.
Thanks John, I’m happily listening now 🙂
Paul.
Whenever you have reasons to suspect that something, if it existed, would be too hard to compute: what should you think about it? In another domain this is like the question whether there exist living beings outside the solar system: if they do exist, our life expectancy will prevent us from meeting them – in exactly the same way as it already prevents us from applying brute force to solve P=NP.
The clearcut notion of existence of first order logic should be questioned. In real life, the things which “don’t exist” are precisely those you can’t feel with any of your senses and can’t compute with your brain. In mathematics, existence is decided by the axioms and a chain of deduction called a proof… plus one requirement: this proof must be understood by mathematicians! If we accept to take into account this additional requirement, then both notions of existence now coincide.
> Is the wanton conceptual destruction wrought by P=NP a material reason to believe its opposite?
No, but it’s one more reason to “believe a proof that they are equal, if correct, would be very difficult. So difficult that no one will find it for years, decades, or perhaps forever”.
If it seems too good to be true, it probably is. Imagine we knew how to solve all NP-complete problems in an efficient way: our level of development would be increased dramatically so as to shortcut the “normal course” of evolution – whatever this means. In any case it would allow us to stop thinking, which is probably not a good thing for the human race. So there *has* to be a barrier between us and a “magic algorithm”. Maybe P=NP yields a logical contradiction, or maybe it’s too hard for us too prove, or maybe it’s undecidable… who knows? We’re allowed too choose our prison but we’re not allowed to escape it.
“if it is too goo to be true, it probably is”. Thats a vey academic viewpoint. What about “if it is too bad to be false”?
You may as well choose this one if you want. But as John Sidles points out, being unprovable is practically equivalent to being false. 🙂
Wonton destruction of everything that’s believed to this point isn’t reason to assume anything. Observation, however, is a good point for assumtion. It’s assumption based on observation that allows for heuristic methods for solving NP problems in many cases.
Really, if P=NP, then that’s boring. Proving P=NP seems like the apocolypse, because it kills so many qustions and areas of study. All that fun, just going away in an instant.
P=/=NP is interesting. Not just because of what it would mean for preserving what we have now or improving understanding of complexity, but what a solution does for problem solving in general.
The leaps in understanding needed in problem solving, to simply solve this problem, is far more interesting than what could be done if P=NP.
As and observer it’s facinating that the problem is so difficult, but the idea that the problem is unsolvable seems a little silly. The structure of NP-Complete problems must be identical, as solving one NP-complete problem solves an equivilant NP-Complete problem of a different type, and something within the structure of these problems either allows or prevent’s solving in polynomial time, in every case. Now that’s a “duh” statement, but the idea we can’t understand the interaction between elements in these problems well enough to know how these interactions effect the difficulty of solving the problem is, IMHO, a bit nuts.
Really, it’d be a whole mess of trouble if we truely couldn’t understand interactions between a finite number of elements in a problem.
The completeness of the permanent is another example of of the “serendipity” pointed out by Jin-Yi. Indeed, the permanent is hard in all fields except those of characteristic 2.
The permanent is of course easy in the latter fields since it is equal to the determinant.
But the completeness proofs, which do not use linear algebra at all, just happen to fail in char. 2 (because they use the constant 1/2). Could this be pure chance ?
Excellent observation! 🙂
No, I think it’s just because they use the constant 1/2.
Another instance: GF(2^n) can be represented so that squaring is just shifting, and x*y = ((x+y)^2 – x^2 – y^2)/2, so we have a linear time algorithm for multiplication as well as addition (where you can also compare, I think), no? No—the pesky 1/2 does not exist.
If pi were the full circumference of the unit circle, then Euler’s equation would be even more mystical:
e^{i*pi/2} + 1 = 0
with division and the constant 2 now included, where they combine to give 1/2. Which tells me 1/2 is sui-generis, so what you say is not “a matter of chance”. Also 2 is a kind-of non-prime… 🙂
The issue of “the wanton conceptual destruction wrought by P=NP” should suggest dumping the current notion of complexity as being based on unknown properties of infinitely many algorithms. Indeed, NP-complete problems remain hard even if P=NP, because efficient algorithms are useless when nobody can prove that they exist!
The classical definition of complexity was meant, IMHO, for hiding its true nature which belongs to physics. If complexity was a purely mathematical concept, then what sense would it make to solve some problems more quickly by means of quantum mechanics?
Serge,
You might be confusing Computational Complexity (the cost of computing) with Complexity Theory (the butterfly effect and behavior of systems). See the GLL Post 2/21/2011.
Jim,
I’m not confusing these two notions. I’m actually speaking of the computational concept of complexity which I do believe possesses a really fruitful physical aspect. The current debate about quantum computers has been quite revealing about this.
Sorry, Serge. I stand corrected.
WHY P=NP IS UNDECIDABLE
There are two competing interpretations of the computational complexity of problems, i.e. two very different models – one for P=NP and one for P!=NP. In both models, the starting point is program complexity, i.e. the asymptotic behavior of programs when the size of the input data increases. This notion has the same meaning in both models. By contrast, each model has its own definition of problem complexity. For convenience, I’ll call the model of P=NP the mass-model and the model of P!=NP the existence-model.
P=NP
All problems in NP have a polynomial algorithm. Therefore, all problems in NP are potentially of “equivalent” difficulty – apart from the coefficient of the polynomial. So, how can it be that we experience different complexities for SORTING, FACTORING and SAT? That’s because, in this model, each problem is provided with an inherent complexity that slows down the process of finding an efficient algorithm to it. The analogy comes from special relativity: you may instantly accelerate a particle to the speed of light if and only if the particle has no mass. But whenever you try to accelerate one which possesses a mass, it will take infinite time to reach the ultimate speed. No need to say, SORTING – like all the problems known to be in P in the existence-model – are analogous to particles with no mass. FACTORING is a sort of medium-mass particle, whereas SAT it a sort of heavy particle, for it takes more time to get “accelerated” – that is, to find more and more efficient algorithms to it – than does FACTORING. In this model, a computation is indeed regarded as a kind of motion and problem complexity as a kind of mass. While all problems actually possess an efficient algorithm, the optimal solution takes longer to be found when the problem is more complex. When a polynomial solution has been found in finite time, computer scientists say that it’s an “easy” problem – which means “in P” in the existence-model.
P!=NP
Only the easiest problems in NP possess a polynomial algorithm. In this model, whenever a problem fails to be provided with a polynomial algorithm, the explanation is straightforward: it is conjectured that there is no such algorithm. For example, SAT doesn’t have a polynomial algorithm. Neither does FACTORING – as most computer scientists seem to believe. But in any case, it’s still believed that the most efficient algorithms for FACTORING are more efficient than the most efficient algorithms for SAT. Computer scientists express this opinion by saying that SAT is a harder problem than FACTORING.
Now, you just have to pick you favorite interpretation of problem complexity. Both are completely equivalent for all practical purposes. Mathematicians will probably stick to the more traditional existence-model, as they’re in the habit of ignoring questions of time in their reasonings. But physicists might actually prefer the mass model because it looks like a mere restatement of the basics of special relativity. In any case, such a dual interpretation is possible only with an undecidable problem. No need to lose sleep at night…
Of course, I’m well aware that the true P?NP question is about deciding it within the existence model only. However, the above reversal of viewpoint looks interesting in itself. It could prove even more fruitful than the original problem, for the official notion of complexity doesn’t seem to lead very far.
The difficulty with the “mass model” is that however hard it is to find an algorithm, it’s only a constant cost. Constant cost (or even constant factor cost) doesn’t mix well with asymptotic complexity: you get the same big-oh no matter the constant. In fact, if SAT is in P, we already have a poly-time algorithm for it:
http://en.wikipedia.org/wiki/P_versus_NP_problem#Polynomial-time_algorithms
Generally speaking, given any axiom system, there is a program we already know how to write, with the same big-oh as the optimal, provably correct program’s big-oh (which we may not know). So I am not sure what can be said about the “mass” model without some strong sharpening of the ideas.
I was aware with this algorithm, however, I never asked myself if it has an asymptotically optimal running time. But in fact, it has, indeed. Nice 🙂
“[…] although with enormous constants, making the algorithm impractical” (same paragraph in Wikipedia).
It’s quite likely that both models don’t fit perfectly with one another, after all. I suppose that in a sociological depiction of the computing experience, the easy problems would have to be solved by practical algorithms…
Thank you Luke for your answer. In fact, the mass model is a sociological one. I don’t know if it’s possible to make it completely rigorous. However, trying to solve a problem often feels like having to carry a big mass and the brain is sometimes compared with a muscle. In this model, problem solving isn’t done at constant cost because the number of mathematicians working on the same problem tends to grow exponentially, while the improvements on the algorithms are often constantly infinitesimal. It is this ratio which counterparts the notion of asymptotic behavior in the existential model. Mine is just an attempt to get rid of the usual appeal to the infinite collection of all Turing machines. To me, it’s like trying to base a study of literature on the set of all possible books – as in Borges’s short story “The Library of Babel”, which depicts a library containing every possible 410-page text.
I was also inspired by Scott Aaronson’s “Multiple-Surprises Argument” in “Reasons to believe”:
“For P to equal NP, not just one but many astonishing things would need to be true simultaneously. First, factoring would have to be in P. Second, factoring would have to be as hard as breaking one-way functions. Third, breaking one-way functions would have to be as hard as solving NP-complete problems on average. Fourth, solving NP-complete problems on average would have to be as hard as solving them in the worst case. Fifth, NP would have to have polynomial-size circuits. Sixth, NP would have to equal coNP.”
So, if P=NP, there really has to be something else that prevents everything from being as easy as pie!
Here’s my provisional conclusion for now: there’s no such thing as an accurate model of feasibility. The P?NP question is the punishment we get for oversimplifying the very notion of complexity.
> “For P to equal NP, not just one but many astonishing things would need to be true simultaneously. […]”
This judgement of Aaronson seems flawed to me. All problems in NP might indeed be of complexity P, but for as long as an efficient solution hasn’t been found to them they still behave as if they were difficult. An algorithm which hasn’t been found yet – or which is galactic – can’t be run, and this is the only reason why all problems don’t look equally difficult.
So we’re led to wonder what makes it more difficult to find an efficient solution to some problems than to others, rather than wondering which problems possess an efficient solution and which don’t. Why is FACTORING harder than SORTING? Because an easy solution was found for the latter, and none for the former. And why is it so? Because SORTING was more likely to get an easy solution than FACTORING.
Yes, complexity is ultimately nothing but the result of a low probability. In fact, SAT certainly has probability zero of getting an efficient solution – which doesn’t mean that it doesn’t exist, but which might well keep making SAT look forever difficult…
And the same premature feast is still going on. In his latest blog entry, the same author quoted some recent book: “If P=NP, then people could design more effective cancer therapies, solve more crimes, and better predict which baseball games would be closely-matched and exciting (yes, really).”
But unfortunately – no, not really. Not if all polynomial algorithms for an NP-complete problem have to be galactic. Not if no existing computer can run them. Not if their Kolmogorov complexity must exceed the intelligence of all the living beings in this Universe…
Just because P=NP, that doesn’t mean pigs can fly!
The risk of a theoretical collapse is nothing compared to a collapse of reason. If P=NP, everything becomes easy and the mental layers in ours minds become useless. The feeling of time disapears, everything being reversible. And probably, no need for deep thinking either. Evolution seems to have made the choice that P!=NP. Not a theorem though, just that with P=NP we’d be closer to madness. Nature has preferred structure over effiency, making our minds unable to prove P=NP. It’s a sound choice and we should feel thankful for it.