Group Testing For The Coronavirus
Plus other mathematical ideas that may be helping

|
| History of Econ. Thought src |
Robert Dorfman was a professor of political economy at Harvard University, who helped create the notion of group testing.
Today Ken and I discuss this notion and its possible application to the current epidemic crisis. We also discuss other mathematical aspects that have clear and immediate value. Update 03/19/20: Israel Cidon in a comment links to an actual implementation of group testing for the virus up to 64 samples from the Technion.
The novel coronavirus (and its disease COVID-19) is the nasty issue we all face today. I live in New York City and can see the reduced foot traffic every day. The issue is discussed every minute on the news. I hope you are all safe, and well. But we are all worried about this.
The point of group testing is that it can reduce the number of tests needed to find out who has the virus. I assume that we are not using Dorfman’s idea because it does not apply to today’s testing. But it seems like it could fit. One issue is the need for more individual testing kits. As we write this, the US is still well short of the needed supply of kits. Are there situations where group testing can still help economize?
Group Testing
Dorfman created the notion of group testing in 1943. You could say he was driven by the need to test light bulbs:

As Wikipedia group-testing article explains:
[Suppose] one is searching for a broken bulb among six light bulbs. Here, the first three are connected to a power supply, and they light up (A). This indicates that the broken bulb must be one of the last three (B). If instead the bulbs did not light up, one could be sure that the broken bulb was among the first three. Continuing this procedure can locate the broken bulb in no more than three tests, compared to a maximum of six tests if the bulbs are checked individually.
Okay, Dorfman’s motivation was not light bulbs. It was testing soldiers during WWII for a certain disease, that will go unnamed. This type of testing reduced the number of blood samples needed. What was analogous to connecting groups of light bulbs into one circuit was combining portions of individual blood samples into one sample. If it tested negative then that entire group could be dismissed without further testing.
Fewer Kits
The point of using group testing is made stark when you think about recent issues with cruise ships. On one ship there were around 

According to the current outbreak maps, known cases in the US are still fairly sparse. Those in New York are mainly in the city, Westchester, and along the Hudson River to Albany. Let’s say we wish assurance that all non-virus related admits to a hospital are free of the virus. Can group testing apply?
The original version of group testing would apply if it were deemed mandatory that all new admits give a blood sample. Some kinds of coronavirus test kits use blood samples. Taking blood samples might however be as costly and intrusive as having the individual tests to begin with. There are other kinds of tests involving taking swabs, but it is not apparent whether those samples can be combined at scale as readily as blood samples can.
At least the idea of group testing has interesting connections to other parts of theory. Here is a 2000 survey by Ken’s former Buffalo colleague Hung Ngo with his PhD advisor, Ding-Zhu Du, where the application is to large scale screening of DNA samples. Hung and Ken’s colleague Atri Rudra taught a course in Buffalo on group testing in relation to compressed sensing. More recent is a 2015 paper that tries to solve problems of counting the number of positive cases, not just whether they exist.
Other Mathematical Effects
As we write, New York Governor Andrew Cuomo has just declared a cap of 500 attendees for any assembly. This is forcing the suspension of Broadway shows among many other activities. Yesterday the entire SUNY system joined numerous other institutions in moving to distance-only learning after this week.
The cap is based on the likelihood of 
Here is a graph from a PSA item posted just today by Alex Tabarrok for the Marginal Revolution blog (note that the calculations are by Joshua Weitz of Georgia Tech):

The 

Now here is the most important point. It’s the size of the group, not the number of carriers that most drives the result.
This involves comparing two partial derivatives. The item gives a brief worked-out example without using calculus.
I, Ken, have been connected this week to another example. I was statistically monitoring the World Senior Team Chess Championship, which began last Friday in Prague. Almost 500 players in teams of 4 or 5 players took part. Initially the players were roughly evenly divided between two halls. Effective Tuesday, a cap of 100 was declared for the Czech Republic, so more playing rooms were found and spectators were banned. Today, however, after an update on the density of cases in the Czech Republic, the cap was lowered to 30 effective tomorrow. Thus the tournament was forced to finish today, two rounds earlier than planned. Even though chess events have a lower size footprint than all of the spectator sports whose seasons have been suspended in recent days, the growth of the outbreak is making cancellation the only reasonable policy for all but the smallest events.
The main purpose of these and other social isolation measures is to flatten out the growth of cases. The target is not just to contain the outbreak but also to stay below the number of serious cases that our treatment systems can bear at once. Here is one of numerous versions of a graphic that is being widely circulated:

The graphic is not necessarily talking about reducing the number of cases total. The area under both curves is the same. A sentence in accompanying article—
If individuals and communities take steps to slow the virus’s spread, that means the number of cases of COVID-19 will stretch out across a longer period of time.
—seems to imply that “the number of cases” is the same in both scenarios, but stretched out over time in the latter. The point is how the stretching keeps the
We certainly hope that isolation can reduce that number—i.e., that containment data out of Southeast Asia in particular holds true, as opposed to fears being voiced in the West that the virus will spread to a large percentage of the population over time. See charts here, especially chart 7. This tracking map has free access and is updated daily.
What governs the spreading process? This is being understood via simple mathematical models of contagion, such as come from percolation theory and its associated 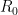
Open Problems
Is group testing a practical mechanism for mapping and constraining the epidemic? How can we promote the understanding of mechanisms and equations and models, not only for those shaping policy but for us who must abide by it and know why.
Update 3/24: Article on FiveThirtyEight.com about how COVID-19 tests work.
Update 6/27: This is still being talked about.
[added note about UB and others going to online learning, added small-event qualifier about chess, clarified COVID-19 is the disease, added map link and two updates.]


My question about the virus is does cancelling sports events and large gatherings really have a significant effect on slowing down the virus spread? If we model interactions between people as a graph, even if it is very sparse, it can still be very connected. Isn’t there an almost 100 chance that a sparse graph is an expander graph? I think I heard something like this somewhere.
In large gatherings, the one-to-all broadcast situation is what matters. In a graph—in percolation theory—each edge has a probability of not transmitting. The powering when
of not transmitting. The powering when  works against the expansion property.
works against the expansion property.
Dear Craig:
A sparse graph is indeed likely to be an expander. The difference I wonder is that our graphs are not arbitrary. They are not planar, but they do have some local geometric structure. This raises some interesting questions of how to model the graphs that actually arise.
Best, be safe
Dick
Random geometric graphs, created by first taking a random point process in R^d and then e.g. connecting point closer than some specified distance, are known to not be expanders, with high probability.
Large expander graph cannot be “nicely” embedded in R^d for any d.
Seems to me there needs to be a post about estimates of the inception and effect of herd immunity, say in the US on COVID-19. On the one hand, there are Harvard reports that the expected infection penetration of COVID-19 on the US population is 40 to 70 percent. Assuming a kill rate of 1% the estimates of 240K dead, worst case, seems to need a really big herd immunity contribution. Is that even plausible. It is also interesting how much testing you need to do in order to establish herd immunity estimates for your model locally, statewide, and nationwide. Can you use the population of France as a proxy for the US in terms of population distribution wrt COVID-19 herd Immunity?
There is some evidence COVID-19 is spread by droplets rather by aerosols, implying they spread in a limited radius from an infected person. That would suggest that the danger of public gatherings may be more proportional to the density factor of a crowd than its total size. I.e., 100 chess players spread around a good-sized room may in fact be safer than 30 packed into a smaller venue.
As a complete aside, the unnamed disease in the group test was originally known as the French Disease in Italy and as the Neapolitan Disease in France, while it most probably was introduced to Europe by the Spanish. Widespread misinformation about diseases predates Facebook by quite a few centuries.
And it Turkey it was called “Frengi” though the word Frenk used to be also used generically for all christian Europeans at that time. What is constant is that no one will call something bad with their own (groups’) name, regardless of where it originated.
Just as a followup to my original post (the droplet-borne part, not the xenophobia part), it would be interesting to see a variant of Tabarrok chart where the X-axis is density of people per square meter, not overall crowd size. Such a chart would strongly suggest avoiding mosh pits at rock concerts and the Tokyo subway (which is probably good advice in any case).
There’s obviously a question of dilution and noise in pooled tests (will one positive person show up if you mix five lots of blood together? what about ten? or fifty?). However, another issue about group testing in this context is lag: I don’t know how long the tests take to deliver an outcome. If they take a while, you may be forced to use non-adaptive test strategies (which can be asymptotically OK in sparse regimes, but never quite as good as adaptive strategies for finite size problems)
This is all by way of a quick plug for our recent survey monograph on group testing https://dx.doi.org/10.1561/0100000099
Dear Oliver Johnson:
Here is your book info:
Group Testing: An Information Theory Perspective
Matthew Aldridge, University of Leeds, UK, Oliver Johnson, University of Bristol, UK, Jonathan Scarlett, National University of Singapore, Singapore.
Incredible timing. The issue you raise on mixing samples is the key one. We cannot see what is known?
Best, and stay well
Dick
Thanks – it does seem strangely topical right now!
There seems to be some discussion on Twitter as to whether this is a feasible or useful strategy:
Yaniv Erlich argues that it isn’t a good idea https://twitter.com/erlichya/status/1238522385952899074
but some of the comments in the thread he quotes are more positive.
Here is a case count in NYC
https://www1.nyc.gov/site/doh/health/health-topics/coronavirus.page#cases
Google already does this to a degree with outbreak detection (statistical prevalence of certain search terms for a geofenced area … mapped by IP). Do you think the same technique could create a weighted partitioning scheme for geographical areas (with the query density as the test, to help establish risk factor/areas more likely to test positive if sampled?)
Sounds like a practical idea that should be explored. The common test is PCR (detects known pattern in DNA https://di.uq.edu.au/community-and-alumni/sparq-ed/sparq-ed-services/polymerase-chain-reaction-pcr) which is based on swab taken from nose or throat. I asked somebody who is familiar with PCR and it seems to be sensitive enough to be tested in a bulk, not sure what the limitation is and also what are the false positive and negative rates. It is in principle a fast test so the delay should not be a limitation especially as it is being automated. There are of course more efficient algorithms than the original Dorfman but they require more than 2 samples. I am sure they can be found in the book mentioned above. Random example: https://www.researchgate.net/publication/220682820_Explicit_Nonadaptive_Combinatorial_Group_Testing_Schemes.
Group testing works well if you know in advance that the probability of infection is low. It can be very useful if you would like to sample a large population to discover, say an epidemic breakout after social isolation is stopped. Not sure who you should convey this to. Maybe the the epidemiology department in the med-school at your institute.
Already tested in RAMBAM medical center Technion) in Israel https://www.youtube.com/watch?v=vxs11ryS9Dg&feature=emb_logo. They showed they can pull up to 64 samples.
Not sure about US.
Israel, thank you very much for this. We have added an update at the top of the post. Thanks to others above as well.