Galactic Algorithms
Algorithms with huge running times

David Johnson is a renown computer theorist who was awarded the 2009 Knuth Prize, for his seminal contributions to theory. He is famous for: his many great papers on various aspects of algorithmic theory, his classic book “Computers and Intractability: A Guide to the Theory of NP-Completeness” with Mike Garey, and his continuing interest in the practical aspects of computing. He has been the driving force behind many experimental studies of how well algorithms perform on “real” data.
Today I want to discuss the issue of galactic algorithms. A galactic algorithm is an algorithm that is wonderful in its asymptotic behavior, but is never used to actual compute anything.
The power of asymptotic analysis is that we can predict the behavior of an algorithm without ever running it. This ability is one of the great achievements of modern complexity theory. That we can predict, often with great accuracy, how fast an algorithm would run, if executed, is indeed a major triumph. Yet, often algorithms are created that cannot be run because their running time is too large, or there are less sophisticated ones that would out-perform them on realistic data.
The name “galactic algorithm” is due to Ken Regan—I suggested the concept, but he came up with the name—my original name was terrible. Not actually “terrible,” but not as good as Ken’s. Perhaps there is a better name, for now it is the one I will use.
The thought behind it is simple: some algorithms are wonderful, so wonderful that their discovery is hailed as a major achievement. Yet these algorithms are never used and many never will be used—at least not on terrestrial data sets. They do, however, play several important roles in our field, which I will dicuss in the next section.
Galactic Algorithms
The danger in giving examples is that I may make some people upset—this is not my intent. If they are the proud creators of an algorithm they may be offended if I point out that their prize creation is galactic—that it will not get used in practice. I think this misses several key points. There is nothing wrong with galactic algorithms, they abound throughout complexity theory. They are still of immense value for several reasons:

Some Examples
Here are some examples of galactic algorithms. Again please keep all of the above in mind. This is not any criticism.


Note, this is clearly a galactic algorithm: even for modest approximations the exponent is huge, and the algorithm cannot be used. Yet researchers in algorithmic game theory would be thrilled if one could prove a bound of the form

where the dependence on
If and when practical quantum computers are built Peter’s algorithm will be one of the first algorithms run on them. Right now it is a galactic algorithm. But, perhaps it is the best example of the importance of galactic algorithms. Peter’s great breakthrough in the discovery of his algorithms has lead to the creation of thousands of new results and papers.
Neil Robertson and Paul Seymour proved their famous graph minor theorem. This theorem proves that every minor closed family 
For any instance
that one could fit into the known universe, one would easily prefer
to even constant time, if that constant had to be one of Robertson and Seymour’s.
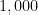
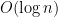
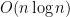
Open Problems
Galactic algorithms can be of immense importance. They can lead to new methods, new directions, and sometimes can be made practical. If you found a SAT algorithm that runs in time bounded by

or proved that any SAT algorithm requires time

then you would be famous. The first would prove P=NP so that would be huge, the later would prove a non-linear lower bound on SAT. That would also be huge—at least to those of us who have tried to prove such theorems.
Is this classification of algorithms useful? What is your favorite galactic algorithm? What do you all think?
Trackbacks
- Algoritmos galácticos « Mbpfernand0's Blog
- How Ryan’s Circuit Lower Bound Works « Gödel’s Lost Letter and P=NP
- Predictions: Past And Future « Gödel’s Lost Letter and P=NP
- We Believe A Lot, But Can Prove Little « Gödel’s Lost Letter and P=NP
- Testing Galactic Algorithms « Gödel’s Lost Letter and P=NP
- A Breakthrough On Matrix Product « Gödel’s Lost Letter and P=NP
- Just a bit faster « Dango Daikazoku
- A Brief History Of Matrix Product « Gödel’s Lost Letter and P=NP
- The Travelling Salesman’s Power « Gödel’s Lost Letter and P=NP
- Why We Lose Sleep Some Nights « Gödel’s Lost Letter and P=NP
- Details Left To The Reader… | Gödel's Lost Letter and P=NP
- Galactic Sortning Networks | Gödel's Lost Letter and P=NP
- Shifts In Algorithm Design | Gödel's Lost Letter and P=NP
- Computational group theory, 1 | Peter Cameron's Blog
- Why polynomial time is called “efficient”? | CL-UAT
- The Other Pi Day | Gödel's Lost Letter and P=NP
- October Links and Activities | Mental Wilderness
- select refs and big tribute to empirical CS/ math | Turing Machine
- What is an Efficient Algorithm? – Ignou Group
- Goldilocks Principle And P vs. NP | Gödel's Lost Letter and P=NP
- Lost in Complexity | Gödel's Lost Letter and P=NP
- Integer Multiplication in NlogN Time | Gödel's Lost Letter and P=NP
- Integer Multiplication in NlogN Time - 2NYZ
- New top story on Hacker News: Galactic Algorithms – News about world
- New top story on Hacker News: Galactic Algorithms – Golden News
- New top story on Hacker News: Galactic Algorithms – Outside The Know
- New top story on Hacker News: Galactic Algorithms – Hckr News
- New top story on Hacker News: Galactic Algorithms – World Best News
- New top story on Hacker News: Galactic Algorithms – Latest news
- Galactic Algorithms – INDIA NEWS
- Galactic Algorithms | My Tech Blog
- Galactic Algorithms (2010) | Mark Beazley | MarkBeazley.Com
- Galactic Algorithms (2010) – Hacker News Robot
- Numbers Too Big for Our Universe | Gödel's Lost Letter and P=NP


A nice example of what I think is a galactic algorithm is Gentry’s fully homomorphic encryption scheme: it’s a great achievement with many potential applications, yet the constants involved are too large to make the algorithm practical.
An overview can be found here. Numbers can be found here.
Alex,
I think cryptography is good source of galactic algorithms. However, there is a good history of converting galactic ones into those that can actually be used. Perhaps it another whole discussion.
But thanks for your comment.
Actually, Gentry’s scheme has been implemented: see here. While it is not yet “efficient”, I think this shows that it is not “galactic”.
Jonathan,
Good point. This the reason I stay away from crypto algorithms. Sometimes a “galactic” algorithm can be used for special cases, or it can be converted to a non galactic one.
dick
Nice perspective.
When I read your introduction I immediately thought of certain (randomized) datastructures such as skip or jump lists that provide good behaviour on paper but are awful to implement.
I find skip lists easy to implement, and often assign them to my undergraduate data structures and algorithms class. Why don’t you like them?
Although I have never used skip lists, when I first learned about them, I remember thinking that they were really elegant from a practical point of view. Any reason one would not use Skip lists? I’d like to know.
Maintaining the correct distribution such that results for expected runtimes stay valid can be nasty, more so for jump than for skip lists. Assuming you have a well tested library, sure, use them; but if you have to do your own implementation you might be better off using a simpler data structure.
Nice choice of name! This is one of the reasons I think people overestimate the impact that a proof of P=NP. P,NP are often presented as though, if somebody proved P=NP, suddenly the entire world would change, cancer would be cured, distant space would be explored, unicorns would be discovered, etc. (Ok, I exaggerate a little) It could quite well be, though, that the polynomial-time algorithms are so inefficient in practice that they never see any use.
A galactic algorithm is an algorithm that is wonderful in its asymptotic behavior, but is never used to actual[ly] compute anything.
The famous quantum factoring algorithm of Peter Shor may or may not be a galactic algorithm.
Until a quantum computer is built, all of our quantum algorithm are galactic algorithms. They have better asymptotics but have never been used in practice.
Shouldn’t that be:
“The famous quantum factoring algorithm of Peter Shor is simultaneously both a galactic algorithm and not a galactic algorithm.”
😉
Maybe we should say, ‘Shor is a terrestrial algorithm for galactic hardware’!
What percentage of algorithms published in STOC/FOCS and SODA could be characterized as galactic?
95% for STOC/FOCS and 75% for SODA.
There are “galactic” open problems in mathematics too: problems that are open in principle, but solved in practice. Of the Clay Millennium Problems, both “Navier-Stokes Equations” and “Yang-Mills Theory” are good candidates for status as galactic open problems.
If you are reading this on an LCD screen, then the glass for that screen likely was fabricated by Corning’s flow-fusion process, whose practical engineering requires in-depth investigation of the Navier-Stokes equations, as instantiated by the flow of hot glass. Thus the Navier-Stokes equations provide the foundational resources—both mathematical and physical—for the ten-billion-dollar enterprise that is Sharp’s Green Front Sakai manufacturing facility. That the Navier-Stokes equations are not known to be well-posed is, we thus appreciate, not an obstacle to creating large enterprises based upon them.
The Clay Millennium “Yang-Mills Theory” problem can be regarded, in essence, as the “Navier-Stokes Equation” problem lifted to a complex state-space. For example, the classical dynamical roles of viscosity and thermalization lifted to the quantum dynamical processes of measurement and decoherence. As with classical dynamics, the resulting quantum dynamical systems formally are ill-defined and/or infeasible to simulate … and yet in practice, quantum dynamical simulations are well-posed and tractable.
Indeed, the most-cited article in all of physics—by a huge and ever-increasing margin—is Walter Kohn and Lu Jeu Sham’s celebrated 1965 article “Self-Consistent Equations Including Exchange and Correlation Effects”, which introduced what are today known as the Kohn-Sham equations. The Kohn-Sham equations work well—often astoundingly well—in finding the ground states of (in effect) any quantum system for which thermalizing dynamics drives the system to a ground state … even though adversarially posed instances of this same problem are thought to be computationally intractable.
A similar pattern is evident even in the case of matrix products … the large systems of linear equations that arise in practice, generally exhibit sparse and/or factored structures that, when exploited, yield computational speed-ups that are substantially greater than achieved via Strassen-type “galactic” algorithms.
The overall lesson, perhaps, is that one feature that qualifies an algorithm as “galactic” is that is effective even against adversarially posed problem instances. And yet the problems that Nature poses to us seldom are generated adversarially, but rather arise via dynamical processes that generically are hot, dissipative, and noisy … and thus are generically tractable.
So while it is nice to know that galactic algorithms exist—or not, as the case may be—we appreciate that galactic algorithms often are over-powered for solving non-adversarial problem instances. It is heartening too that the conjectured non-existence of a desired galactic algorithm (or even its proved non-existence) need not obstruct our seeking algorithms that (for practical purposes) provide the same capabilities.
I have trouble believing what you’re saying about Strassen’s algorithm. I’ve had my students implement it as their second programming assignment for years. As long as you do the right thing and “cross-over” — switch back to regular matrix multiplication once you’re small enough where that’s clearly better — using Strassen’s proves to be a significant improvement on conventional machines with conventional programming languages. The switchover point is quite small — in the tens in practice — so using Strassen’s on matrices in the hundreds by hundreds (and crossing over when the recursion hits a small enough point) is a clear win.
I’m not sure where this “conventional wisdom” on Strassen’s comes from. Maybe for specialized implementations where matrix multiplication is more frequently used this isn’t the case. But in my experience Strassen’s should be used often; perhaps others can comment on whether it is used frequently on standard mathematical software engines.
I would like to say that theoreticians are in fact not the best judges of the *practical* value of their algorithms. Very often, algorithmic engineering makes a big difference on whether a particular high-level algorithmic idea is useful or not. This cannot be found out by simply thinking about asymptotics.
Michael, the Wikipedia reference says in its entirety—bold and italics mine:
Practical implementations of Strassen’s algorithm switch to standard methods of matrix multiplication for small enough submatrices, for which they are more efficient. The particular crossover point for which Strassen’s algorithm is more efficient depends on the specific implementation and hardware. It has been estimated that Strassen’s algorithm is faster for matrices with widths from 32 to 128 for optimized implementations.[1] However, it has been observed that this crossover point has been increasing in recent years, and a 2010 study found that even a single step of Strassen’s algorithm is often not beneficial on current architectures, compared to a highly optimized traditional multiplication, until matrix sizes exceed 1000 or more, and even for matrix sizes of several thousand the benefit is typically marginal at best (around 10% or less).
It is possible that the Wikipedia author has drawn only the pessimistic conclusions from its reference. Then again, we could have made Coppersmith-Winograd our reference: how far down do your versions try to push the exponent?
Kenneth —
I read the Wikipedia article; I just don’t get it. A basic calculation (which I give to my class) says that under reasonable assumptions (mult/add ops all take one time cycle, say) the crossover point for Strassen’s is in the small tens. With various pipelining or other architectural features I understand this might not be exact. But again, my students implement this every year for a homework assignment (on their laptop, or any machine they like) and the crossover point is generally in the tens for reasonable implementations. I didn’t read the paper referred to in the Wikipedia article, but a basic back-of-the-envelope calculation will show that Strassen works just great for reasonable sizes. (The same sort of calculation will show that if you DON’T cross over, and do Strassen’s all the way down to 1 by 1 or 2 by 2 matrices, then yes, it’s not practical for reasonable sizes — and I assumed that’s where this strange folklore had arisen.)
Well, this is interesting… The cited paper by D’Alberto and Nicolau is definitely attentive to crossover points (they call it “RP” for recursion-truncation point). I knew Alex Nicolau while he was a student of Gianfranco Bilardi at Cornell. We covered Strassen in my seminar, and I’ll delegate them to see what our high-performance computing people say…
@Michael: I don’t know what “basic calculation” you’re using, but brute force matrix multiplication can be vectorized, unlike Strassen’s, and brute force has good cache behaviour, unlike Strassen’s. Brute force also parallelizes more simply and more uniformly. These are all huge factors that make brute force much better on architectures since about 2001.
Sorry, I forgot to put numbers to those terms to explain why they make a difference.
Vectorization allows one to perform, for example, 4 multiplies on adjacent data in one instruction. The independence of adjacent groups of 4 elements in brute force matrix multiplication allows multiple of these quadruple-multiplication instructions to be run at the same time in a single core. These two together can produce an 8x to ~24x computation time speedup, depending on the circumstances.
It also allows for faster memory accesses, and when combined with the good cache behaviour of brute force, this can produce a memory access time speedup factor of 10 or more (depending on how bad the memory access times are for what’s being compared.)
Multi-threading can also give big speedups, but it’s hard to quantify the difference between the two algorithms without specific implementations.
Anyway, in a nutshell, it takes a big matrix (155,201 x 155,201) for the tiny difference in exponent to beat a 10x speedup.
If I understand well your conversation, the point is the following: If you don’t use very sophisticated methods of pipelining or such things, then Strassen’s algorithm is useful. But as you begin using sophisticated methods, Strassen’s has less good behavior than classical matrix multiplication algorithm.
In other words, if you mainly are a mathematician with no specific knowledge about fine programming tricks, then use Strassen’s algorithm. But if you are a true geek, then do by-hand optimizations on the classical algorithm and it will run faster!
As was said, the problem is that you need to compare a highly tuned version of the O(n^3) matrix multiplication algorithm with one using Strassen’s method. I show my 2nd year students http://dl.dropbox.com/u/726501/Intro_and_MxM.pdf to give them an indication of how much difference coding improvements can make to matrix multiplication. My understanding is that optimised Level 3 BLAS implementations now do actually incorporate Strassen’s algorithm at least in some cases, although finding this stated definitely in their documentation is non-trivial. There are also numerous papers discussing when Strassen’s algorithm is useful and when not (e.g. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.137.5979 ). The dependence on the computer architecture makes the question rather system specific it seems.
Hi all. I can believe this — I think the statement that a “highly tuned” version of standard matrix multiplication can beat Strassen’s up to big matrix sizes makes perfect sense (and is consistent with my arguments/findings). So now I guess how much of this is done automatically by compilers for you — as far as I know, my students just throw three for loops at the thing for the standard algorithm (which is just what I’d do).
In any case, I’ll still say that Strassen’s wouldn’t be on my list of galactic algorithms.
I think the BLAS implementation of matrix multiply is an order of magnitude faster than the naive C++ code. So that means compilers still have a long way to go!
This is roughly a factor of 10 slower than a reasonably tuned (ie, an afternoon of work, no use of inline assembly or multiple cores) algorithm. If you pretranspose the second matrix before doing the multiply, then you’ll be able to avoid a lot of cache misses. If you also block the multiplies, then you can eliminate almost all cache misses, and with a bit of care you can even make the data dependencies simple enough that a compiler (even gcc) can automatically vectorize your code.
Ah yes, thanks for mentioning the pre-transposing. My comments also assumed pre-transposition (or symmetric matrices).
As for GCC automatically vectorizing the code, unfortunately, they only have an alpha version of the compiler flag that allows 4x loop unrolling for vectorization, meaning that you need to compile your own version of GCC to get it. I was shocked that ftree_vectorize doesn’t already do that, since it then begs the question as to whether ftree_vectorize does anything at all. 🙁
The paper I linked to (which it seems no one read 🙂 ) indicated a 38x speedup by comparing highly optimised BLAS code (which I am assuming is still using the O(n^3) method there) with some naive C code in their particular test. This is before making the code suitable for multiple cores but did include some assembly coding it seems. The reason this whole question is even more unclear than one might think, is that an implementation of Strassen’s algorithm can also be tuned, it has just taken people a while to work out how to do it well and there are only recently benchmarks for such code. In any case, I certainly agree that Strassen’s algorithm is not galactic, although possibly it is continental.
For those who don’t like to follow unverified links, the numbers were, in ms, naive C code 7530, transposed 2275. tiled 1388, vectorized 511, Intel’s BLAS implementation 196, parallel BLAS 58.
Actually this topic brings up another question, algorithms whose naive implementations are far worse than highly tuned ones (and for which this is not universally known/accepted). The two examples I know of are naive matrix multiplication and the use of the FFT for relatively small problem sizes, especially for pattern matching. There are many theoretically interesting pattern matching algorithms (ahem…cough) whose speed relies on the FFT. People are sometimes reluctant to use them in practice as they believe the FFT is only suitable for very large inputs. However, careful use of such libraries as FFTW (and in particular the preprocessing it enables) can make these methods very fast indeed.
In this discussion, Kenneth W. Regan mentioned our ongoing work (with A. Nicolau and G.bilardi), and I think I should write my opinion.
My background: I worked on hybrid recursive algorithms for Strassen/Winograd and we are working on parallel implementations for them (we are seeking publication for an advanced parallel implementation).
(for example
http://www.ics.uci.edu/~fastmm/FMM-Reference/reference.html
)
Let me address directly a few misconceptions:
1) cross over point: since the publication/implementation of the first Strassen algorithm, a few say that Strassen’s is always beneficial, a few say that is not, and some do not care (GotoBLAS is the fastest and they do not care). The truth is in the middle: it is architecture dependent, it is of course matrix type dependent (single, double, single complex and double complex), and it is dependent on the BLAS implementation used to solved the basic computation (the hand tuned kernel)
You may have architectures that have a cross over for N=1,500 in double precision and other for N=7,000 (where N is the matrix size) using the best implementation of MM (by GotoBLAS/ATLAS/MKL or just name it). We may discuss why such a large difference another time.
This is puzzling for somebody because there is not a simple and single claim. In practice, you may have to try on your system. For authors and publishers alike, a paper will be a much better if there is a claim either way, because they think readers are accustomed to expect a claim either way (or the other way around).
Personally, I found this mixed scenario exciting, because it requires a little more effort than just back-of-the-envelop estimation and represent how a old and well know problem can be always fresh and changing.
2) performance advantages: we have measured between 10-25% speed up using 2-3 levels of Strassen/Winograd w.r.t. the best MM implementation. Again, a few may consider 10% at best marginal but it is not! Look the 10% in this way: You are using the fastest MM implementation (i.e., GotoBLAS) achieving already 95% of peak performance, and thus any further improvements may provide at most 5% improvements (but they won’t) and it will require quite a genius for each specific architecture. Now, if you can achieve at least 10% with no extra effort, that 10% is not marginal, it is the only improvement you can get.
3) Strassen/Winograd should always be considered in combination with the best implementation of MM. In fact, S&W algorithms extend the performance edge of the fastest MM implementations: they are not there to substitute them but to complete their performance range.
Are there other examples of galactic algorithms that were eventually implemented after computer architectures changed? I understand why you call Shor’s algorithm galactic, but it seems to be very different from the other algorithms. Shor’s algorithm has very reasonable exponent and constants and certainly will be implemented when we build quantum computers. Early work on quantum fault-tolerance thresholds, by Shor and others, was even more “galactic,” a proof of principle but the constants were terrible.
If David Johnson’s quote is correct, then Robertson and Seymour’s algorithm will never be used. Quantum algorithms have never been used, but will be. Maybe the definition, “A galactic algorithm is an algorithm that is wonderful in its asymptotic behavior, but is never used to actual compute anything” should be changed to be an algorithm that has never been used, but whose existence still drives entire research programs.
There’s another name for these, PTAS 🙂
Another example is the ellipsoid method for linear programming. Theoretically important, but slow in practice.
Simplex* is also interesting algorithm for solving linear programming in that it requires exponential time in the worst case, but seem to perform well in practice. In a way, it has the opposite problem as the ellipsoid method.
* http://en.wikipedia.org/wiki/Linear_programming#Simplex_algorithm_of_Dantzig
The dichotomy between these two methods has probably driven people to investigate average-case performance more.
What would you call this type of algorithm?
When I started out as an Operations Researcher in college, what we called Simplex was “best algorithm around, good average-case behaviour for an exponentially hard problem, probably because most real-world problems aren’t ridiculously ugly.”
Then Ellipsoid showed up, with complexity L*N^6, where L was also pretty large, which pretty much fits Johnson’s “Galactic Algorithm” scale, theoretically extremely interesting, not only because it wasn’t exponential but because it pushed us to use an entirely different set of models and tools to look at the problems with, but too slow to use in practice. And then Karmarkar figured out how to do it in L*N^3.5, which was actually usable.
What about the opposite? Algorithms with provable “galactic” lower bounds that work well in practice? (Not to mention semi-algorithms that terminate in practice…)
I like the term “galactic algorithms”! It’s better than my “not even theoretically practical” algorithms 🙂
Here is one personal example (apologies for the self reference): Venkat Guruswami and I showed that one can list decode rate folded Reed-Solomon codes up to
folded Reed-Solomon codes up to  fraction of errors in time
fraction of errors in time  . Designing a “non-galactic” list decoding algorithm for such codes has a big (potential) practical payoff.
. Designing a “non-galactic” list decoding algorithm for such codes has a big (potential) practical payoff.
Q. How Galactic is O(n15)?A. It is 1013 years, n = 100, –on the fastest (single) processor known
today.
The polynomial complexity turns out to be very un-intuitive and illusive.
We don’t even have to go as far as O(n100). The time complexity,
T(n) = O(n15) = O(1013) YEARS!! (for n=100)(For n=10, T(n) = 3.65 days)
This calculation is based on the following parameters:CPU: IBM 5.6GHZ, Z196 with 92 instructions/secNumber of clock cycles in the smallest step = 1(This is the absolute lower bound on the number of clock cycles, ignoring any
constants, and assuming a sequential computation.)1 year = O(107) seconds.
Did I missed something here?
Sorry folks– my first xhtml did not work very well (I used tex4ht)
I mean to say (n^15) = 10^13 years.
1 year = 10^7 seconds.
I suppose this should sort out the display problem
A few examples that come to my mind:
* Reingold’s logspace algorithm for undirected s-t-connectivity. One of the greatest theoretical results of the past decade, but I don’t know that anyone has ever bothered to implement it (doesn’t it run in something like n^8 time with fairly large constants?)
* The HILL paper that constructed a PRNG from any one-way function — as I recall, their construction resulted in something like a O(n^40) factor in the running time of the PRNG. Still a very deep theoretical result.
* Does Martin Furer’s integer multiplication algorithm count? Wikipedia tells me it’s only asymptotically faster than Fourier methods in the multitape model, but I don’t know that much about it.
On another level are the problems where it’s a deep result that they’re decidable at all, but the algorithms are asymptotically terrible. The most prominent example I know of is the star height problem for regular languages, but I think equivalence of deterministic PDAs might also qualify. (Problems in the Robertson-Seymour class have a similar feel.)
I’m surprised that Chazelle’s famous “linear time” triangulation algorithm didn’t come up. It’s one where the algorithm is so incredibly complex that just writing code to represent the algorithm would probably be a galactic task. 🙂
It’s still an open problem in Computational Geometry as to whether there’s a reasonable linear time triangulation algorithm.
There’s an algorithm (with supposed polynomial runtime) for testing isomorphism of two knots that takes hundreds of pages to describe. Writing actual code would me a mammoth task.
*be
Sorting: Miklos Ajtai, János Komlós, and Endre Szemerédi proved the existence of a sorting network of {O(\log n)} depth and {O(n \log n)} size.
Hasn’t this been resolved by means of Benes networks [Benes 65] of depth {2 \log n} and width {n}?
See e.g. [Gocal, Batcher 96].
When I hear “galactic algorithm” it actually makes me think more of the proposal to implement HALT by sending a mathematician through a rotating black hole.
I think the remarkable thing about “galactic algorithms” and the asymptotic paradigm is how often it is the case that polynomial-time algorithms are either practically good themselves, or have practically good variations, or at least indicate that the problem is practically solvable albeit by a different algorithm.
I like Gil’s post very much. It is an interesting exercise to catalogue the good mathematics that historically has arisen from asking “How do non-galactic algorithms work, exactly?”
“Non-galactic algorithms exploit symmetry” leads us to group theory.
“Non-galactic algorithms exploit thermodynamics” leads us to entropy and symplectic flows.
“Non-galactic algorithms exploit noise” leads us to quantum information theory.
“Non-galactic algorithms exploit evolutionary structure” leads us to graph theory.
All of these are good examples of what von Neumann called “the reinjection of more or less directly empirical ideas … that preserve the freshness and vitality of [mathematics]”.
It is challenging and fun, therefore, to discern and distill new mathematical ideas that are already implicitly exploited—often without being explicitly recognized—in today’s non-galactic algorithms.
I’m afraid I don’t see why “galactic” seems apt. Is it supposed to suggest their bigness? Speaking of big things in the universe, this brings to mind a quote by Richard Feynman:
You could call them “slow start” since they perform badly on small inputs, but do better as the input size grows. I don’t particularly like this name either though, since it would overload the term “slow start”, but I bring it up to avoid being totally non-constructive.
I think that any PTAS that is not FPTAS is galactic:.
Homomorphic encryption is an interesting example because even if the algorithms are of low complexity (say cubic in n), that is enough to make them near-galactic. A conventional database transaction that burns a fraction of a cpu-second on today’s computers might easily do tens of billions of basic gate operations during its execution (e.g. a floating point multiplication that takes one cpu cycle might be 1000’s of gate operations). If n is a few billion then n**3 is at least interplanetary, though maybe not galactic.
The opposite of intergalactic might be submicroscopic. Think of the union-find problem whose complexity involves the inverse Ackermann function.
On the issue of Strassen’s algorithm, I would concur with Mike: the algorithm is certainly not “galactic”, since it has been used to actually compute something. If you google “strassen algorithm” you can find relevant references on the first page, e.g.,
this one.
Piotr,
Strassen is one of those that is time dependent. There was time certainly galactic. Now unclear.
Hi,
I guess it all comes down to the fact that the question “is an algorithm galactic” is not fully defined. There is the language ambiguity (what time frame “is never” refers to) as well as the complexity of the subject matter (what do we mean by “used”). Nothing wrong with that – the subject matter is complex, and it is better to rely on common-sense interpretations instead of over-specifying things.
I am assuming the time frame of the last few years, and that being a part of a major software library (see the link from my previous post) qualifies as “used”. In this case, the answer is clear: Strassen’s algorithm is not “galactic”. I am sure going beyond the top 10 Google hits would supply additional arguments.
Note that this does not contradict the earlier posts or studies. I am sure that under many circumstances highly tuned “standard” MM beats Strassen’s for small/moderate inputs. It’s just that there are many other factors: the “highly tuned” algorithm might be more complex to code; it might be proprietary; it might be advantageous not to tune the the algorithm to make it more architecture-independent (as in “cache aware” vs “cache oblivious”); one might really want to optimize the running time when it matters, i.e., for “large” inputs; etc etc.
Overall, I think “galactic algorithms” is an interesting and important notion. So we should be careful not to end up lumping together those algorithms that are highly impractical with those that are used in practice. That would not lead to a very meaningful outcome.
Richard,
I disagree — Strassen’s is clearly not time dependent. It may be hardware dependent, but as long as you assume there’s a chip somewhere that’s NOT able to parallelize various certain low-level operations but needs to multiply matrices, then Strassen’s is a win.
I guess I’m reiterating Piotr’s points. (Thanks, Piotr!)
It’s amazing to me that nobody has mentioned the AKS primality test.
The description of Robertson-Seymour is a bit fuzzy as given – the sentence about finding a forbidden minor from F is not really clear. More precisely Robertson-Seymour showed that any minor closed class F has a *finite* list of forbidden minors and (separately) that testing for the presence of any fixed minor could be done in polynomial time (by a galactic algorithm). The forbidden minors for a class F are naturally not FROM the class F, because by definition they lie outside it.
So the galactic algorithm to which you refer is really an algorithm for “determining that a graph is IN a minor-closed class F by determining the presence or otherwise of an excluded minor FOR F”.
But in fact, the galactic part is really just the minor-testing. The other part is even worse than galactic – you don’t in general know the finite list of minors to test for, nor do you have any way of finding them.
There are two categories of galacticness I think. One is where we suspect the implementation would not be fast for any reasonably sized inputs. However, to reach truly interstellar proportions, don’t we also want that simply implementing the algorithm at all is deemed to be utterly impractical. I am not aware, for example, of a single implementation of Coppersmith-Winograd matrix multiplication, quite apart from how long it might take to run it.
My favorite galactic algorithm is an $O(n^{81})$ algorithm by Rune Lyngsoe:
http://dblp.uni-trier.de/rec/bibtex/conf/icalp/Lyngso04
which can be seen as an algorithm solving a problem lying between the cubicly solvable maximum weighted matching problem and some NP-complete problem in bioinformatics. Of course it is intractable, but it clearly shows how an easy problem goes to a hard problem.
Galactic algorithms are common in cryptanalysis – for example, Biryukov & Khovratovich’s attack on AES-256 which has complexity 2119.
“galactic” = “useless”?
from,
No I would say that galactic is an algorithm that we will never use. By still one that gives insights into the structure of the problem. We also have many cases were galactic algorithms could eventually be made into real algorithms.
There’s also Szemeredi regularity lemma which leads to galatic property testing algorithm for the problem whether a graph has a triangle.
I think “Hutter Search” is a great example of a galactic algorithm; it’s incredibly simple and optimally solves a huge range of problems (anything which can be brute-forced).
We run two algorithms concurrently: the problem-solver brute-forces a solution while the optimiser brute-forces a provably-faster problem-solver.
Since the optimiser is independent of the input data, all optimisations take O(1) time, so Hutter Search is equivalent to a (provably-)optimal algorithm.
This is useful in AI, where many self-improving/learning algorithms can solve a range of problems ‘given enough time’; Hutter Search shows us that this is not enough, we must perform experiments to see how effective these algorithms are, even if our analysis shows they’re optimal.
I give my favorite galactic algorithm but its also a test of your spam filters.
Given a set of n numbers you want to find a number in the top half.
You can make n comparisons per round. How many rounds do you need?
Alon and Azar showed that you can do this in log*n + 2 but no better than log*n -4.
This is galactic in that you would need n to be larger than blah blah for the bounds to even make sense. And to top it off, the proof is nonconstructive.