Practically P=NP?
Solving is believing

|
|
Cropped from source. |
Boris Konev and Alexei Lisitsa are both researchers at the University of Liverpool, who work in Logic and Computation. They have recently made important progress on the Erdős Discrepancy Problem using computer tools from logic. Unlike the approach of a PolyMath project on the problem, their proof comes from a single program that ran for just over 6 hours, a program administered only by them, but mostly not written by them.
Today Ken and I wish to talk about their paper and two consequences of it.
Their paper (update) can be read at two levels. On the surface the paper is about the famous discrepancy conjecture of Paul Erdős, which we have talked about before. I will state the precise conjecture in a moment, it was said that previously the best lower bound for a certain “constant” ג was 1 and they moved it to 2. Since Erdős conjectured that a finite ג must not exist, that is it is unbounded, this is a long way from solving the problem. Yet it is the first nontrivial result of any kind on this famous problem.
Note, we are experimenting with using Hebrew letters to denote constants that aren’t. The logical wording of Erdős’ conjecture is that for any 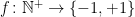
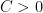


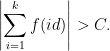
Thus this says that no matter how cleverly the sequence of 

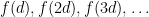
whose sum (or its negative) exceeds 
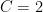
Theorem 1.
ג

Since ג is an integer this means ג 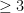

Un-Bespeakable Proofs?
The abstract of their paper includes a word that I and probably most fellow Americans would blip on:
For the particular case of
a human proof of the conjecture exists; for
a bespoke computer program had generated sequences of length 1124 of discrepancy 2, but the status of the conjecture remained open even for such a small bound.
Looking in my English-English/English-English dictionary, I find the phrase “bespoke tailor,” but nothing to do with bespoke programs. Of course Ken from his long time in England knew the word means “by commission” or “custom-made,” as in custom-tailored. Well custom tailors have dwindled even more on this side of the Pond. The first consequence I see in their paper is that this may start happening for hand-made proofs and programs too.
Note their paper is entitled “A SAT Attack on the Erdős Discrepancy Conjecture.” That’s right, SAT as in complexity, or really SAT as in solver. What they did was “meta”: they coded their requirements for a proof of ג
-
First they construct a long finite sequence of discrepancy 2, meaning that 2 is the maximum of all finite sums
in it.
- Then they show that no longer such sequence can be found.
The latter, the UNSAT proof, is what’s not checkable by hand. It prints to a 13-gigabyte file. Ken counts his nearly 200 gigabytes of chess analysis data as being 2 kilobytes to a “page,” so by that measure their proof fills 6.5 million pages. As several news articles point out, this dwarfs the 15,000 pages of the classification of finite simple groups, and even tops the estimated 10 gigabytes of the entire printed content of Wikipedia in English.
Such a length seems unspeakable. If the authors required us to verify a custom-tailored program on top of that, we’d probably agree. However, they dress for success with a mail-order wardrobe of SAT solvers. Hence their proof is unbespeakable. Once you take the measurements they need—their logical requirements and SAT encoding—you can order the computation from any suitable e-tailer for SAT. As our friend Gil Kalai is quoted as saying:
“I’m not concerned by the fact that no human mathematician can check this, because we can check it with other computer approaches.”
Some Discrepancy Numbers
That ג 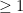
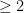
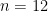

For the more liberal notion that allows arithmetical progressions to begin at any number 
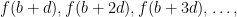
the discrepancy has been known since 1964 to grow as at least the fourth-root of the length of the sequence, with a multiplier of 

If ג 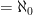
For any
there is an
such that for all
, every sequence of length
contains a finite
-anchored progression whose sum (or its negative) exceeds
.
Thus if Erdős’ conjecture is true, then this defines a function 

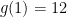




A Word on How They Do It
Computing 

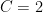
The much more difficult part came when they increased the length to 1161. Showing that there is no sequence—that no sequence enables each of its ![{[-2,\dots,+2]}](https://s0.wp.com/latex.php?latex=%7B%5B-2%2C%5Cdots%2C%2B2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Konev and Lisitsa have a separate page on the details of their encoding, helping others to check their work. And also to appreciate it, because it needs some cleverness. An “obvious” encoding requires too many variables. One of the keys in making SAT attacks of this type is in how one encodes the problem.
They are currently working on 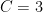

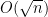



P=NP?
Their paper can also be read at another level, below the surface, that reflects on complexity theory. Their paper shows that there are SAT solvers capable of solving hard natural problems in reasonable time bounds. What does this say about the strong belief of most that not only is 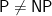
I wonder sometimes if we in complexity theory are just plain wrong. Often SAT solver success is pushed off as uninteresting because the examples are “random,” or very sparse, or very dense, or special in some way. The key here, the key to my excitement, is that the SAT problem for the Erdős problem is not a carefully selected one. It arises from a longstanding open problem, a problem that many have tried to dent. This seems to me to make the success by Konev and Lisitsa special.
John Lubbock once said:
What we see depends mainly on what we look for.
Do we in complexity theory suffer from this? As they say across the Pond, this is bang-on. According to our friends at Wikipedia, Lubbock was:
The Right Honourable John Lubbock, 1st Baron Avebury MP FRS DCL LLD, known as Sir John Lubbock, 4th Baronet from 1865 until 1900, [a] banker, Liberal politician, philanthropist, scientist and polymath.
I know he lived many years ago, but note he was a polymath: hmmm… Meanwhile I remember when another Liverpool product came across the Pond 50 years ago, which some say “gave birth to a new world.”
Open Problems
The main question is can we advance and prove ג 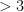
The real long-term question, for both of us, is what does this type of success say about our beliefs in complexity theory? Does it not shake you a tiny bit, make you a wee bit worried, that we may have made a serious error. That our “belief” that SAT is hard is wrong? Ken has a motive given here for trying out some #SAT solvers, which are out there too.
Update: “Un-bespeakable” programming is a good context to note this just-released demo by Stephen Wolfram himself of his Wolfram Language.
[re-cast intro slightly, added update, changed poorly designed LaTeX \gimel to HTML 1490]
Trackbacks
- Polymath5 – Is 2 logarithmic in 1124? | Combinatorics and more
- Shtetl-Optimized » Blog Archive » The Scientific Case for P≠NP
- P≠NP asymptotically…P=NP practically | The Furloff
- Could We Have Felt Evidence For SDP ≠ P? | Gödel's Lost Letter and P=NP
- Is This a Proof? | Gödel's Lost Letter and P=NP
- Lint For Math | Gödel's Lost Letter and P=NP
- Case Against Cases | Gödel's Lost Letter and P=NP
- The Shapes of Computations | Gödel's Lost Letter and P=NP
- Frogs and Lily Pads and Discrepancy | Gödel's Lost Letter and P=NP
- Terence Tao magic breakthrough again with EDP, Erdos Discrepancy Problem, topnotch links | Turing Machine
- select refs and big tribute to empirical CS/ math | Turing Machine
- Predictions For 2019 | Gödel's Lost Letter and P=NP
- Code It Up | Gödel's Lost Letter and P=NP


So $P=NP$ is your conjecture?
We have opposite beliefs, as we stated here. But we agree on factoring being in P, or at least in classical BPP.
Incidentally, the proof for n=12 is pleasant to do by hand—it involves essentially no backtracking. One index value can be left entirely unassigned when you complete the reasoning—which is it?
Thank you. I do believe P=NP is possible but solving sat in 2^(logn)^(1+epsilon) time may be more likely (give creativity a chance). And that a 2^(logn)^(1+epsilon) time solution should address all the classes in the hierarchy $L \subseteq P \subseteq UP \subseteq NP ?=coNP \subseteq PH \subseteq PSPACE$ in one shot in a wholistic way.
I really enjoy the integer factoring posts on this blog, it would be great if there could be some more in the future. Your recurring idea that factoring should be attacked by finding an easy way to calculate n! mod x seems like a good starting point. I would like to ask if you know of any algorithm for calculating the double factorial: (2^u – 1)!! mod 2^n for some u<n which runs in O(n^x) time. I think such an algorithm exists but i don't know if there's already a trivial way to do it. It won't help with factoring integers, but any shortcut in calculating factorials would be a nice small insight i think.
I have great disbelief factoring could be solved by calculated $n! mod N$ quickly (or at least the easiest way to solve factoring with be by calculating) in poly time particularly because 1) it would solve factors in a given range problem in poly time( and this problem is NP Complete) and still would not resolve Berman-Hartmanis hypothesis (I believe any proof of P=NP should resolve many fundamental questions in complexity theory in one stream) 2) $n! mod N$ directly does not resolve DLog (which I believe is related to factoring).
@j
In the special case of (n – 1)!! mod N with n and N being powers of 2, i think theres a possibility of finding an exact result quick. In the general case however it is sufficient to determine if n! = 0 mod N which could be a lot easier and don’t allow for factors in a given range to be determined. I have no specific idea how one would attack the later problem though.
“….still would not resolve Berman-Hartmanis hypothesis ‘explicitly’!”
“…. $n! mod N$ directly does not resolve DLog ” should be “…. $n! mod N$ directly does not ‘directly’ resolve DLog (it resolves via solving an NP complete problem which is factors in a given range)”
Just one more point. Essentially the possibility of http://en.wikipedia.org/wiki/Berman%E2%80%93Hartmanis_conjecture seems to weigh against P=NP. What do you think about this conjecture? Is there a way ti disprove this?
It is amazing how people favoring any bias towards P==NP belief like to remain behind the curtains!
I feel that in order to decide whether the success of a SAT solver in this instance has any bearing on the likelihood that P=NP, I would want to know whether it came as a great surprise to Konev and Lisitsa that it worked in the time it did. I would expect not, and that they would have done a feasibility study first. Also, the fact that the problem is, as you say, not carefully selected, doesn’t necessarily count as evidence in favour of P=NP. For many NP-complete problems, one has to be fairly careful to find hard instances, so if you don’t carefully select your instance there isn’t a strong reason to expect it to be hard.
If somebody put in a random instance of the hidden clique problem (take a random graph of size n and take, say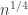 vertices randomly and join all the edges between them, and then challenge an algorithm to find the resulting clique) and a SAT solver solved it quickly, then I would certainly sit up and take notice. But here I don’t see a compelling reason to have expected in advance that what Konev and Lisitsa did was impossible for some fundamental reason (which doesn’t stop me being surprised and impressed that they actually did it).
vertices randomly and join all the edges between them, and then challenge an algorithm to find the resulting clique) and a SAT solver solved it quickly, then I would certainly sit up and take notice. But here I don’t see a compelling reason to have expected in advance that what Konev and Lisitsa did was impossible for some fundamental reason (which doesn’t stop me being surprised and impressed that they actually did it).
I once researched an opposite idea: at critical parameter junctures, instances with short descriptions tend to be harder. In one mass sense this is trivially plausible—in cases where “random” instances are distributionally easy, the rest can be harder on the whole. I’ve had cases using the Buchberger algorithm in “Singular” where I really expected to get answers in reasonable time but it became a total memory-overflowing bog. This was even on Scott Aaronson’s small determinant and permanent challenge from 2007, which was still unanswered when he reiterated it in 2011. My guess is that in fact the UNSAT part was longer than expected, but Konev and Lisitsa had enough oomph that it didn’t matter. (I am a wee bit surprised that one can see n_C jump from n_1 = 12 to n_2 = 1161 and then expect n_3 to come in under 15,000, but perhaps it’s an odd-even thing, with n_4 being prospectively gigantic.)
I share your surprise about n_3. There are some weak reasons to think that the bound might be of an -ish type. If you take
-ish type. If you take  , then
, then  , then continue in an arithmetic progression to a third term
, then continue in an arithmetic progression to a third term  and work out
and work out  , you get around a million. So I would expect the bound for n_3 to be much larger than 15,000, but my confidence in that expectation is not very high.
, you get around a million. So I would expect the bound for n_3 to be much larger than 15,000, but my confidence in that expectation is not very high.
The heuristic reasons for e^x^2 behavior may still prevail and the difficulty of finding a satsfying assignment may be related to how rare they are.
had a feeling you were gonna cover it! its not often one scoops the legendary blogger RJL. think this is a very important technique of using SAT solvers for thm proving & think there may be an amazing generalization. note also the MSM has covered this proof in two places, new scientist & the independent. more details, great moments in empirical/experimental math/TCS research, breakthrough SAT induction idea… and a new tcs.se question on the same subj, similarity of sat instances, detecting/analyzing/mapping… maybe some more reaction later
vznvzn,
Thanks for the pointers.
Going into the same direction, a SAT-based approach has recently been used in order to show optimality of some classes of sorting networks:
http://arxiv.org/abs/1310.6271
Looks as if SAT solvers are at a stage nowadays where they can push bounds for “real world” problems from combinatorics.
Very Nice post! My feeling regarding Konev and Lisitsa’s resuly is similar to what I felt regarding Appel and Haken proof of the 4CT that it is a scientific achievment which goes beyong the scope of the original problems. (I had a similar feelings toward computerized chess.) I am not sure that it is likely that computerized proof will lead human to see patterns that will allow general proofs.
גיל
GK think there are surprises in store where computers will help identify patterns that are also human-recognizable, but its indeed a new research program & huge challenge and that wikipedia-size proof seems hopeless/discouraging at moment. its early, rome wasnt built in a day. it will require more human-computer collaboration than exists currently in TCS but that is not a bad thing overall. think of the discovery of the Higgs particle and all the theorists/experimentalists working in a large/productive collaboration/synergy. it will require a new way of thinking, its a paradigm shift in progress/play right in front of our eyes.
Gil,
Thanks for your kind comment.
“I am not sure that it is likely that computerized proof will lead human to see patterns that will allow general proofs.” It is still in very early stages of interaction of complexity theory and meaning.
Reblogged this on xiangyazi24.
A very nice text which incidentally says the very same thing about this work on the discrepancy theory and P vs NP as I did say some weeks ago:
http://motls.blogspot.com/2014/02/erdos-discrepancy-conjecture-proved.html?m=1
Complexity theorist / quantum computation expert Scott Aaronson of MIT would loudly disagree with me but he is just being heavily prejudiced and irrational.
Lubos Motl
Thanks for the pointer to your earlier post
“he is just being heavily prejudiced and irrational” — Lubos Motl
Such projection.
“Bespoke” is in common use among programmers generally as a good way of describing the cost differential between mass-market software and software written custom to one’s needs. It also sees some particular currency with game programmers to describe game content that is carefully authored rather than procedurally generated.
want to add a comment, initially held my tongue on this (after now drawn back to this post as now refd by curmudgeon Aaronson). far be it for me to point this out (the irony) but my browser counts 26 references to NP on this page (not counting new ones added in this comment). re:
no one else is calling this out but holy cow RJL this is some really fuzzy headed thinking here (and am now trying to remember which blog of yours seemed the most outlandish & psychedelic, meant to bookmark that one, but now its a needle in a haystack!).
hate to rain on this parade so much right down my own alley so to speak, but the paper does absolutely nothing of the sort. it says zilch about NP literally, and imho, nearly zilch about it peripherally/indirectly except circumstantially carrying the fabulous indication that NP complete problems and SAT are a big deal (that was kind of realized decades ago)…..
its a few single instance of SAT solved, which as we all know from basic statistics, correlation vs causation, does not a trend make. what it really shows (at this early pt, with later research along these lines expected), as covered in my latest blog, is that TCS scientists are not really investing much effort into empirical approaches. (wasnt this carried out by mathematicians, really? and isnt there something a bit cognitively dissonant about that?)
Dear Prof Lipton, there has been a new wave of fiery exchanges about the evidence for/against P=NP or the non-existence of it between Scott Aaronson and myself,
http://www.scottaaronson.com/blog/?p=1720
http://motls.blogspot.com/2014/03/pnp-is-conceivable-there-is-no-partial.html?m=1
My guess is that you actually agree with me/us more or less completely but yes, I am also used to the fact that in certain questions that have been dogmatized, people who are professionally involved tend to remain silent. 😉
“My guess is that you actually agree with me/us more or less completely”
Says a self-serving ideologue.
I wanted to share some thoughts about factoring in Moore’s law to question of practical p=np. While some might argue this isn’t important, one has to recognize the physical nature of the problem. TSP can already by driven to O(n^2 2^n) complexity, and since n^2 is quickly dominated by 2^n it isn’t hard to see that Moore’s law can keep pace.
http://thefurloff.com/2014/03/09/moores-law-drives-computational-resources-pnp-practically-part-2/
hi RJL … am taking full credit for recently introducing a very talented cohort “realz” to your blog, he remarked on this pg & then said he disagreed, gasp with my last comment about relationship of EDP to P=?NP question which is the subj of some further attn eg by yourself, Motl/Aaronson etc. encouraged him to reply here but he skipped it, slacker 😛 … anyway we ended up having quite a discussion/debate on this topic here, cs.se chat linked here for interest/convenience of anyone with too much time to kill 😀
P =? NP is intrinsically linked to the entropy constraint.
Today, I posted a preprint showing that connection.
http://vixra.org/abs/1403.0058
Dick and Ken in the entry entitled “Theorems from Physics” also discuss some ideas of my theoretical work (http://vixra.org/author/alexandre_de_castro) on one-wayness.
See the central idea in my current preprint:
http://vixra.org/abs/1403.0058
“In computer science, the P =?NP is to determine whether every language accepted by some nondeterministic algorithm in polynomial-time is also accepted by some deterministic algorithm in polynomial-time. Currently, such a complexity-class problem is proving the existence of one-way functions: functions that are computationally ‘easy’, while their inverses are computationally ‘hard’. In this paper, I show that this outstanding issue can be resolved by an appeal to physics proofs about the thermodynamic cost of computation. The physics proof presented here involves Bennett’s reversible algorithm, an input-saving Turing machine used to reconcile Szilárd’s one-molecule engine (a variant of Maxwell’s demon gedankenexperiment) and Landauer’s principle, which asserts a minimal thermodynamic cost to performing logical operations, and which can be derived solely on the basis of the properties of the logical operation itself. In what follows, I will prove that running the Bennett’s algorithm in reverse leads to a physical impossibility and that this demonstrates the existence of a non-invertible function in polynomial-time, which would otherwise be invertible.”
It seems much more reasonable to say that, practically P≠NP, while we can’t tell a thing theoretically…
The ways by which algorithms are being designed – in a remarkably non computable trial-and-error fashion – by different mathematicians in history, this has never been fully clarified. The design of an algorithm is always the result of some convergent historical process. Therefore, in case this process was doomed to always diverge for some reason, then you’d never come up with the desired algorithm… even though it might still exist mathematically!
Thus if P=NP, I believe it’s physically impossible to come up with a proof. And the icing on the cake: you can use the same argument for explaining why large-scale quantum computers aren’t feasible…
Serge, I am not 100% sure whether I understand why Dr Lipton included the word “practically” in the title, but my guess is that he wanted to say something diametrically different from you did.
He said that P=NP could be true in principle *and* P=NP could even be true “practically” i.e. the relevant fast algorithms could be fast enough so that it would matter even practically. So I think that his “P=NP practically” is an even stronger statement than “P=NP theoretically”.
What you – and others – seem to misunderstand or deny is that even “P≠NP for practical purposes” hasn’t been shown yet (P≠NP is only true if P,NP are redefined to only allow algorithms that are already known as of today), and the Erdös result may be interpreted as a hint that the hypothesized polynomial algorithms could actually be not just polynomial in principle, like googol*N^10,000, but very fast so that it would make an impact even in the practical sense, and not just on the questions in principle.
Thanks Lubos for replying – and sorry, I haven’t got the right “s” on my keyboard. 🙂
I hadn’t noticed that. However, the title was a question, not an affirmation. I think it was due to sound provocative, like some other articles in this blog.
This is exactly my opinion, but with an added condition: the efficient algorithms that solve NP-complete problems will never be known, because they’re not connected to any other knowledge. The problems known to lie in P enjoy the nice property of admitting many different solutions, and these act as limit points in the (topological) solution space. My claim is that all solutions to NP-complete problems are of opposite kind: they’re sort of isolated points in the solution space. The solution they bring is unenlightening. So if you change the slightest parameter in them, then the algorithm will fail. I think their Levin measure is zero.
You know, it’s almost the same thing for a problem, to admit only one solution and to be unsolvable…
Dear Serž (I have lots of such characters on my keyboard LOL),
when you write things like “This is exactly my opinion, but with an added condition: the efficient algorithms that solve NP-complete problems will never be known, because they’re not connected to any other knowledge,” do you realize or agree that such proclamations are nothing else than an unproven prejudice? Or do you believe that you have a proof of that statement?
Why should an algorithm to be found in the future be “disconnected from all other knowledge”? Every new insight in mathematics and science is new in some respect and old in other respects. It is always “connected” but this connectedness is really either ill-defined and subjective or a tautology.
Auguste Comte, a philosopher, would say sometime in the 19th century that the chemical composition of stars would permanently remain unknown, and so on. because you know, stars are so exotic and dangerous and distant and untouchable. It took less than a decade for spectroscopy to emerge and tell us about the finest details about the composition of the stars.
As far as I know, the fast algorithms solving the NP problems may be polynomial, fast even in practice, logical, and connected to lots of other knowledge that the mankind has. Nothing we know contradicts this possibility. I think that you are just making things up and trying to impose your prejudices on others as if they were facts.
Cheers
Lubos
Dear Luboš – cut-pasted from Scott Aaronson’s blog 😉 -,
I’d been wondering why Scott kept replying to you – sometimes even dedicating entire posts to contradict your own prejudices – but now I think I hold the reason: you have a true knack for provocation! One more mystery solved…
By the way, what you call a prejudice is more commonly called a conjecture in mathematics. So, do I believe to possess a proof of mine? No, otherwise it wouldn’t be a conjecture anymore – proven conjectures are called theorems. However, do I have serious reasons for thinking it’s true? Though you forgot to ask, the answer is yes.
A fact that’s disconnected from all other knowledge, this is what Gregory Chaitin calls a theorem that’s “true for no reason”. Those facts will never get a proof and must be taken as axioms.
Thank you for mentioning my compatriot Auguste Comte, but frankly I’m not in the mood for a public discussion with you on anything close to my heart. As a former professional who recently turned into an amateur, I suspect you’re eager to make fun of anyone who’s willing to make the opposite move.
Cheers
Serge
Hello,
I demonstrate that P ≠ NP and P = n, I am ready to publish it on this site, but assured me that the solution will not be stolen?
I am self taught and I found the solution, believe it or not
I have a PDF with 20 pages, if someone guaranteed me that the solution will not be stolen, I am ready to send the solution immediately
My name is Khalid El Idrissi I’m from Montreal.
cordially
“I am ready to publish it on this site”
Whatever for?
“but assured me that the solution will not be stolen?”
Is this a joke?
“I am self taught and I found the solution, believe it or not”
Not, of course.
Hmmm…. I think P=NP and here’s why I think so.
As a SAT (satisfiability) formula, decision versions of optimization problems can be expressed as a conjunction of some BFC (basic feasibility constraints) and an OFC (objective function constraint).
Decision problem = BFC AND OFC.
The generic expression for the OFC is “f(X) >= K” for maximization based problems and “f(X) = K” as it is… You would create a set N = {1, 2, 3, …. K}, and express that there is an injective function from the set F to N…. F is the set of X’s for which f(X) >= K…. this will take a bunch of clauses to express.
But one fact remains true — No matter what the complexity of the problem is (P, NP, NP-complete, Logspace, whatever), the detailed expression for the OFC remains the SAME, as long as the arity of F is the same… If F will consist of vertices, then the arity of F is one… if F will consist of edges, then the arity of F is 2…and so on. (FACT ONE)
The tricky bit is, how to write the OFC as a SAT expression that can be polynomially evaluated… There is a proof that the OFC cannot be written as a Horn formula (but this doesn’t mean that it cannot be written in a way that is poly time decidable).
Here’s something interesting…. the BFC part is a Horn formula for Matching… Not surprising, since Matching is poly time solvable… but what’s more interesting is that the BFC for Max Clique and Max Independent Set are also Horn! And everyone knows that Horn formulas are poly time solvable!
Assume that E (the set of undirected edges) is defined such that if E(x,y) is true, then x (y=z)
AND
[M(y,x) AND M(z,x)] —> (y=z)
AND
NOT [M(x,y) AND M(y,z)].
M(x,y) is true if and only if (x,y) is a matched edge.
BFC for Max Clique — Horn clause again!:
\forall x \forall y [F(x) AND F(y)] —> E(x,y).
F(x) is true if and only if vertex $x$ is picked (or marked)… But note that for the Horn clause condition, only F matters, since F is the only UNKNOWN (yet to be determined)…. If $x$ and $y$ are known, then whether E(x,y) is true can be determined immediately from the input graph — so E(x,y) is a KNOWN quantity…. And in the BFC for Matching, M is the only UNknown.
BFC for Max Independent Set — Horn clause again!:
\forall x \forall y [F(x) AND F(y)] —> [NOT E(x,y)].
Recalling FACT ONE above, it appears that the expression for Matching, MaxClique and Max Independent Set are very similar.
Hope some of the SAT experts here take this and “run with it”.
Oops! Sorry, something got left out during the cut-and-paste above. The description for Matching ought to be as follows:
Assume that E (the set of undirected edges) is defined such that if E(x,y) is true, then x (y=z)
AND
[M(y,x) AND M(z,x)] —> (y=z)
AND
NOT [M(x,y) AND M(y,z)].
M(x,y) is true if and only if (x,y) is a matched edge.
My point being — if someone can show that this “SAT type” of expression for Matching can be evaluated or decided in poly time, then a similar (and poly time decidable) expression can be developed for Clique and Independent set.
Noooo! WordPress has done it again! What’s wrong with WordPress – why does it keep doing this?
One last attempt, using less Math symbols, then I’ll give up:
A sequence is imposed on the set V of vertices… Let E, the set of undirected edges, be defined such that if E(x,y) is true, then x appears before y in the ordered set V…. that is, x is less than y.
The BFC for Matching is the conjunction of the 3 clauses below (for every x, every y, and every z):
(a) If [M(x,y) AND M(x,z)], then (y=z)
(b) If [M(y,x) AND M(z,x)], then (y=z)
(c) If [M(x,y) AND M(y,z)], then (False).
http://arxiv.org/pdf/1509.05363.pdf