Shifts In Algorithm Design
How to find approximate page rank fast, among other things

Jennifer Chayes is the current director of a research lab in Cambridge—that is Cambridge Massachusetts—for a company called Microsoft. She is famous for her own work in many areas of theory, including phase transitions of complex systems. She is also famous for her ability to create and manage research groups, which is a rare and wonderful skill.
Today Ken and I wish to talk about how to be “shifty” in algorithm design. There is nothing underhanded, but it’s a different playing field from what we grew up with.
Ken first noted the paradigm shift in 1984 when hearing Leslie Valiant’s British unveiling of his “Probably Approximately Correct” learning theory at the Royal Society in London. Last year Leslie wrote a book with this title. That’s about learning, while here we want to discuss the effect on algorithm design.
We illustrate this for a paper (ArXiv version) authored by Chayes and Christian Borgs, Michael Brautbar, and Shang-Hua Teng. It is titled, “Multi-Scale Matrix Sampling and Sublinear-Time PageRank Computation.” Since PageRank is a vital application, they don’t want their algorithms to be galactic. They trade off by not having the algorithms “solve” the problems the way we used to.
In The Good Old Days
I, Dick, recall the “good old days of theory.” When I first started working in theory—a sort of double meaning—I could only use deterministic methods. I needed to get the exact answer, no approximations. I had to solve the problem that I was given—no changing the problem. Well sometimes I did that, but mostly I had to solve the problem that was presented to me.
In the good old days of theory, we got a problem, we worked on it, and sometimes we solved it. Nothing shifty, no changing the problem or modifying the goal. I actually like today better than the “good old days,” so I do not romanticize them.
One way to explain the notion of the good old days is to quote from a Monty Python skit about four Yorkshiremen talking about the good old days. We pick it up a few lines after one of them says, “I was happier then and I had nothin’. We used to live in this tiny old house with great big holes in the roof.” …

Today
Those were the days. I did feel like I sometimes worked twenty-nine hours a day, I was paid by Yale, but so little that perhaps it felt like I paid them. Never had to drink a cup of sulphuric acid—but the coffee—oh you get the idea.
Now today, in the 21st century, we have a better way to attack problems. We change the problem, often to one that is more tractable and useful. In many situations solving the exact problem is not really what a practitioner needs. If computing X exactly requires too much time, then it is useless to compute it. A perfect example is the weather: computing tomorrow’s weather in a week’s time is clearly not very useful.
The brilliance of the current approach is that we can change the problem. There are at least two major ways to do this:


This is exactly what Chayes and her co-authors have done. So let’s take a look at what they do in their paper.
PageRank
In their paper they study PageRank, which is the definition and algorithm made famous by Google. It gives a way to rank webpages in response to a query that supplements criteria from the query itself. An old query-specific criterion was the number of matches to a keyword in the query. Rather than rank solely by this count, PageRank emphasizes a general page score. The score is sometimes interpreted as a measure of “popularity” or “authority,” leading to the following circular-seeming definitions:

What the PageRank score actually denotes mathematically is the likelihood that a person randomly traversing links will arrive at any particular page. This includes a frequency 
The situation can be modeled by the classic random walk on a directed graph. We have a graph 





![{M[i,j]}](https://s0.wp.com/latex.php?latex=%7BM%5Bi%2Cj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


![\displaystyle M[i,j] = \frac{\alpha}{N} + \begin{cases} (1 - \alpha)\frac{1}{b} & \text{if~} i \text{~links to~} j\\ 0 & \text{otherwise.}\end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++M%5Bi%2Cj%5D+%3D+%5Cfrac%7B%5Calpha%7D%7BN%7D+%2B+%5Cbegin%7Bcases%7D+%281+-+%5Calpha%29%5Cfrac%7B1%7D%7Bb%7D+%26+%5Ctext%7Bif%7E%7D+i+%5Ctext%7B%7Elinks+to%7E%7D+j%5C%5C+0+%26+%5Ctext%7Botherwise.%7D%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
We can tweak this e.g. by modeling the user hitting the “Back” button on the browser, or jumping to another browser tab, or using a search engine. We could also set 
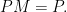
Then the PageRank of node 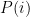
![]()
The issue is: how to compute
The Shifted Problems
The approximation to PageRank is called SignificantPageRank. The paper gives a randomized algorithm that solves the following problem.
Let us be given a graph. Then, given a target threshold
and an approximation factor
, we are asked to output a set
of nodes such that with high probability,
.
This is a perfect example of the shift. The algorithm is random, and the problem is to find not the nodes with a given PageRank, but those that are not too far away.
The nifty point is that the algorithm can tolerate fuzzing the matrix
Given
and
, return a set
columns
and values
such that for all
, and
.
It is important to use this for different values of 
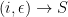
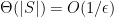
If we picture “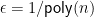
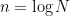
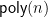

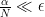

![{M[i,u] = \alpha}](https://s0.wp.com/latex.php?latex=%7BM%5Bi%2Cu%5D+%3D+%5Calpha%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The problem they need to solve for SignificantPageRank then becomes “SignificantColumnSums”:
Given
and
as above, find a set
;
.
An even simpler problem which they use as a stepping-stone is “VectorSum”:
Given a length-
vector
with entries in
, and
and
- output yes if
;
- output no if
, don’t-care otherwise.
The goal is always to avoid looking at all 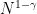
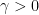

Multi-Level Sampling and Results
Ken and I are interested because these are similar to problems we have been encountering in our quest for more cases where quantum algorithms can be simulated in classical randomized polynomial time. Thus any new ideas are appreciated, and what catches our eye is a multi-level approximation scheme that exploits the requirement of SARA to work for different
The situation for VectorSum is that a probe 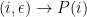
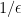

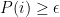

The resulting error has order 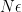
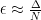

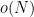
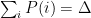

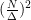
However, they show that by using a different precision 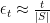
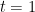
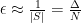
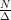
Theorem 1 Given
as above and
, VectorSum can be
-solved with probability at least
and cost

Well in the good old days before LaTeX we wouldn’t even have been easily able to write such a formula with a typewriter, let alone prove it. But it is certainly better than 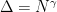
Open Problems
Do you miss the good old days? Or do you like the current approaches? What shifts, what new types of changing the goals, might we see in the future? For clearly today will one day be the “good old days.”
[changed qualifier on “certain pathologies”, may as well footnote here that the “Back” button creates a Markov Chain with memory; changed intro to say British unveiling” of PAC learning.]
Trackbacks
- Let’s Mention Foundations | Gödel's Lost Letter and P=NP
- Top 30 Computer Science and Programming Blogs | Yo Worlds
- Топ-30 лучших блогов о программировании… | IT News
- BLOGS ON COMPUTER SCIENCE | CS SECTION 6B 2013
- Starting off – Shalicia's Page
- TOC In The Future | Gödel's Lost Letter and P=NP
- Computer science – Live Free
- Топ-30 лучших блогов о программировании и вычислительной технике — Rus.Rocks
- Quantum Switch-Em | Gödel's Lost Letter and P=NP


have been looking into a thread somewhat similar to this. spielman came up with a major improvement on fast algorithms for finding graph clusters based on random walks of graphs eg highlighted by Klarreich here: simons institute, Network Solutions:
A new breed of ultrafast computer algorithms offers computer scientists a novel tool to probe the structure of large networks. this meshes with some other theory looking at bounds on random walks, some of which can be computed via pagerank theory. eg this high voted but unanswered question Mixing properties of random walks on graphs. tricky stuff, anyone else, any ideas? yeah randomized algorithms are a whole new way of thinking and seem to be quite fundamental to theory in deep ways that are still yet to be uncovered. although one could observe that they seem to have very close/deep connections with that old concept, nondeterminism.
Dear Profs. Lipton and Regan,
A wonderful column as usual. Prof. Valiant’s seminal paper “A theory of the learnable” was published in the Communications of the ACM in 1984. But according to the web site of The Royal Society, Prof. Valiant was elected as a Fellow only in 1991! So the recollection of Prof. Regan “in 1984 when hearing Leslie Valiant’s inaugural talk on “Probably Approximately Correct” learning at the Royal Society in London” appears to be “probably approximately correct”! 🙂
Don’t ask me why, but I was once invited to explain PAC learning theory to a group of Indian metallurgists. I explained that a PAC algorithm is one that “more or less works most of the time,” and they seemed happy with that.
I shall certainly look up the paper by Chayes et al.
Keep up the good work!
Thanks for the nice comment. By my recollection it was a lecture held in the Royal Society building at Carleton House Terrace. Possibly it was in a building of the University of London, as part of a workshop that had Royal Society sponsorship. I know we went down from Oxford most specifically to hear it—it was more of an “event” and “unveiling” than if Les were giving an invited talk at U. London or Oxford or Warwick, say.
Dear Prof. Regan,
The premises of The Royal Society at Carleton House Terrace are often rented out to host meetings that are unconnected with the Fellowship. So it is quite possible that in 1984 you heard Prof. Valiant talk about PAC learning at Carleton House Terrace. My only comment was that it cannot have been his “inaugural talk” upon being elected as an FRS.
Again, I do really enjoy this blog. I just wish I had the time and energy (not to mention the talent) to keep up with the wealth of information being provided).
Kind regards.
I meant “inaugural talk” about PAC learning—as I said, it was a special event, and it was “at the Royal Society” with their aegis. I knew he was elected in 1991; I didn’t think what I wrote would be taken your way.
Thanks for this post. Seems like there’s always something new I learn even after being in the field for 25 years