Minsky The Theorist
Marvin Minsky’s contributions to complexity theory

|
| Cropped from BBC feature on AI |
Marvin Minsky, sad to relate, passed away last Sunday. He was one of the great leaders of artificial intelligence (AI), and his early work helped shape the field for decades.
Today Ken and I remember him also as a theorist.
Like many early experts in computing, Minsky started out as a mathematician. He majored in math at Harvard and then earned a PhD at Princeton under Albert Tucker for a thesis titled, “Theory of Neural-Analog Reinforcement Systems and Its Application to the Brain Model Problem.” This shows his interest in AI with focus on machine learning and neural nets from the get-go. However, he also made foundational contributions to computability and complexity and one of his first students, Manuel Blum who finished in 1964, laid down his famous axioms which hold for time, space, and general complexity measures.
We will present two beautiful results of Minksy’s that prove our point. AI may have lost a founder, but complexity theory has too. His brilliance will be missed by all of computing, not just AI.
Counter Machines
In 1967 Minsky published his book Computation: Finite and Infinite Machines. This book was really not an AI book, but rather a book on the power of various types of abstract machines.

The book includes a beautiful result which we’ll call the two-counter theorem:
Theorem 1 A two-counter machine is universal, and hence has an undecidable halting problem.
A two-counter machine has two counters—not surprising. It can test each counter to see if it is zero or not, and can add 1 to a counter, or subtract 1 from a counter. The finite control of the machine is deterministic. The import of the two-counter theorem is that only two counters are needed to build a universal computational device, provided inputs are suitably encoded. It is easy to prove that a small number of counters suffice to simulate Turing machines. But the beauty of this theorem is getting the number down to two.
To recall some formal language theory, one counter is not sufficient to build a universal machine. This follows because a counter is a restricted kind of pushdown store: it has a unary alphabet plus ability to detect when the store is empty. Single-pushdown machines have a decidable halting problem. It was long known that two pushdown stores can simulate one Turing tape and hence are universal: one holds the characters to the left of the tape head and the other holds the characters to the right. What is surprising, useful, and nontrivial is that two counters are equally powerful.
I will not go into the details of how Minsky proved his theorem, but will give a hint. The main trick is to use a clever representation of sets of numbers that can fit into a single number. Perhaps Minksy used his AI thinking here. I mention this since one of the key ideas in AI is how do we represent information. In this case he represents, say, a vector 
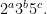
This is stored in one counter. The other is used to test whether say 

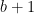
We must add personal notes here. I used this theorem in one of my early results, way back when I started doing research. Ken was also inspired by the connection from counter machines to algebraic geometry via polynomial ideal theory that was developed by Ernst Mayr and Albert Meyer at MIT. The basic idea is that if we have, say, an instruction (q,x--,y++,r) that decrements counter 



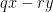


Perceptrons
In 1969 Minksy and Seymour Papert published their book Perceptrons: An Introduction to Computational Geometry. It was later republished in 1987.

The book made a huge impression on me personally, but I completely missed its importance. Also the book is notorious for having created a storm of controversy among the AI community. Perhaps everyone missed what the book really was about. Let’s take a look at what it was about and why it was misunderstood.
The Book
For starters the book was unusual. While it is a math book, with definitions and theorems, it is easy to see that it looks different from any other math book. The results are clear, but they are not stated always in a precise manner. For example, Jan Mycielski’s review in the Jan. 1972 AMS Bulletin upgrades the statement of the main positive result about learning by perceptrons. Inputs are given only in the form of square arrays. The grand effect of this—combined with the book’s hand-drawn diagrams—is a bit misleading. It makes the book not seem like a math book; it makes it very readable and fun, but somehow hides the beautiful ideas that are there. At least it did that for me when I first read it.
It is interesting that even Minsky said the book was misunderstood. As quoted in a history of the controversy over it, he said:
“It would seem that Perceptrons has much the same role as [H.P. Lovecraft’s] The Necronomicon—that is, often cited but never read.”
With hindsight knowledge of how complexity theory developed after the excitement over circuit lower bounds in the 1980s gave way to barriers in the 1990s, Ken and I propose a simple explanation for why the book was misunderstood:
It gave the first strong lower bounds for a hefty class of Boolean circuits, over a decade ahead of its time.
How hefty was shown by Richard Beigel, the late Nick Reingold, and Dan Spielman (BRS) in their 1991 paper, “The Perceptron Strikes Back”:
Every family of
depth-
circuits can be simulated by probabilistic perceptrons of size
.
That is, 
Minsky and Papert’s version of that last fact is what those Perceptrons editions symbolize on their covers. By the Jordan curve theorem, every simple closed curve divides the plane into “odd” and “even” regions. A perceptron cannot tell whether two arbitrary points are in the same region. This is so even though one need only count the parity of the number of crossings of a generic line between the points. Minsky and Papert went on to deduce that connectedness of a graphically-drawn region cannot be recognized by perceptrons either. Of course we know that connectedness is hard for parity under simple reductions and is in fact complete in deterministic logspace.
Missed Opportunities and Understandings
How close were Minsky and Papert to knowing they had
The other key concept they lacked was approximation. This could have been available via their polynomial analysis but would have needed the extra mathematical sophistication employed by BRS: probabilistic polynomials and approximation by polynomials. Perhaps they could have succeeded by noting connections between approximation and randomized algorithms that were employed a decade later by the likes of Andy Yao. Of course we all who worked in the 1970s had those opportunities.
The misunderstanding of their book reminds Ken of some attempts he’s seen to prove that the 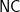







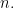

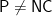
But this conclusion about
[The lower bounds] led to the field of neural network research stagnating for many years, before it was recognized that a feedforward neural network with two or more layers (also called a multilayer perceptron) had far greater processing power than perceptrons with one layer. … It is often believed that [Minsky and Papert] also conjectured (incorrectly) that a similar result would hold for a multi-layer perceptron network. However, this is not true, as both Minsky and Papert already knew that multi-layer perceptrons were capable of producing an XOR function.
One can judge our point further relative to this in-depth paper on the controversy.
Not Missing the Frontier
None of this should dim our appreciation of Minsky as a theorist. We offer a simple way to put this positively. The two-pronged frontier of circuit complexity lower bounds is represented by:
- What is the power of counting not modulo 2 but modulo 6?
- What is the power of threshold circuits of depths 2 or 3? And what is the power of arithmetical circuits of the same depths?
We haven’t cracked counting modulo 6 any more than counting modulo any composite 
Well, a perceptron is a one-layer threshold circuit with some extra AND/OR gates, and modular counting is the first nub that Minsky and Papert identified. They knew they needed some extra layers, understood that connectedness on the whole does not “simply” reduce to parity, and probably flew over the import of having an extra factor in the modulus, but the point is that they landed right around those frontiers—in 1969. They were after broader scientific exploration than “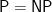
Open Problems
Our condolences to his family and the many people who worked with him and knew him best.
[word changes toward end: “probabilistic analysis” -> “polynomial analysis”; “connectivity” –> “connectedness”]


Dear Professors,
We pretend to show the answer of the P versus NP problem. We start assuming the hypothesis of P = NP that will lead us to a contradiction. The argument is supported by a Theorem that states if P = NP, then the problem SUCCINCT HAMILTON PATH would be in P.
In this Theorem, we take an arbitrary succinct representation C of a graph G_{C} with n nodes, where n = 2^{b} is a power of two and C will be a Boolean circuit of 2 * b input gates. Interestingly, if C is a “yes” instance of SUCCINCT HAMILTON PATH, then there will be a linear order Q on the nodes of G_{C}, that is, a binary relationship isomorphic to “<" on the nodes of G_{C}, such that consecutive nodes are connected in G_{C}.
This linear order Q must require several things:
* All distinct nodes of G_{C} are comparable by Q,
* next, Q must be transitive but not reflexive,
* and finally, any two consecutive nodes in Q must be adjacent in G_{C}.
Any binary relationship Q that has these properties must be a linear order, any two consecutive elements of which are adjacent in G_{C}, that is, it must be a Hamilton path.
On the other hand, the linear order Q can be actually represented as a graph G_{Q}. In this way, the succinct representation C_{Q} of the graph G_{Q} will represent the linear order Q too. We can define a polynomially balanced relation R_{Q}, where for all succinct representation C of a graph: There is another Boolean circuit C_{Q} that will represent a linear order Q on the nodes of G_{C} such that (C, C_{Q}) is in R_{Q} if and only if C is in SUCCINCT HAMILTON PATH.
We finally show R_{Q} would be polynomially decidable if P = NP. For this purpose, we use the existential second-order logic expressions, used to express this graph-theoretic property (the existence of a Hamilton path), that are described in Computational Complexity book of Papadimitriou: Chapter "5.7 SECOND-ORDER LOGIC" in Example "5.12" from page "115". Indeed, we just simply replace those expressions with Universal quantifiers into equivalent Boolean tautologies formulas.
Certainly, a language L is in class NP if there is a polynomially decidable and polynomially balanced relation R such that L = {x: (x, y) in R for some y}. In this way, we show that SUCCINCT HAMILTON PATH would be in NP if we assume our hypothesis, because the relation R_{Q} would be polynomially decidable and polynomially balanced when P = NP. Moreover, since P would be equal to NP, we obtain that SUCCINCT HAMILTON PATH would be in P too.
But, we already know if P = NP, then EXP = NEXP. Since SUCCINCT HAMILTON PATH is in NEXP–complete, then it would be in EXP–complete, because the completeness of both classes uses the polynomial-time reduction. But, if some EXP–complete problem is in P, then P should be equal to EXP, because P and EXP are closed under reductions and P is a subset of EXP. However, as result of the Hierarchy Theorem the class P cannot be equal to EXP. To sum up, we obtain a contradiction under the assumption that P = NP, and thus, we can claim that P is not equal to NP as a direct consequence of applying the Reductio ad absurdum rule.
You could see the details in:
https://hal.archives-ouvertes.fr/hal-01249826v3/document
A correct proof of P=NP can never rule out another correct proof of P!=NP.
This is mathematics!
best,
Rafee Kamouna.
Maybe you should read this:
<>
You could see more in
https://en.wikipedia.org/wiki/Reductio_ad_absurdum
Is this blog post really the place for this?
Hi Dick
I’d just like to mention that Marvin’s “Computation: Finite and Infinite Machines” is an “intrinsically beautiful book” in all the ways a book can be beautiful. One of them was Marvin’s favorite ploy of “understanding things in more than one way”, and some of these ways were truly sweet. Just personally, this book made an enormous impression on me kind of “musically” and it affected the ways in which I thought about things afterwards, despite that none of the stuff I did was very much like the book’s subject matter. Newton’s Principia had a lot of the same effect: the way Newton went about his business in that book was also just excruciatingly beautiful.
I think we were all touched deeply in one way or another by Marvin.
Best wishes
Alan
:star: 💡 ❗ a brilliant thinker who seems to have lost some interest in the field he pioneered eg power of neural networks. did he have anything to say about deep neural nets last few years? its very interesting that the same day in the news, google deepmind introduces a grandmaster level Go algorithm via deep learning that is regarded by many experts as (yet another) breakthrough for deep neural nets.
also, its a natural question of whether multilayer networks would be limited in the same way as 2-layer networks. did minsky & papert identify it as a key open problem? or did they gloss over it? or maybe even avoid it because it did not fit into the framework of limitations they identified? sometimes just pointing/ admitting/ conceding to major terra incognita outside of the bounds of given theorems can be helpful to later researchers. re your old post on “no-go theorems”…
Minsky also studied minimal undecidable problems: how simple can a question be, and still be undecidable?
More precisely, how small can a universal Turing machine (UTM) be?
To define “small” it is not enough to consider “number of states”, as we can encode much of the state by keeping parts of the state in the symbols written (for example the symbol read can encode whether to go left or right). Using such tricks, one can get a 2-state UTM (with a very large tape alphabet.) On the other hand, it is not hard to build a UTM with a tape that uses 2 symbols. A natural measure of the size of the UTM is to consider the product
(number of states) x (number of symbols in the tape alphabet).
This is essentially the size of the table that defines the machine.
In 1962 Minsky exhibited a 4-symbol, 7-state machine, which improved on his previous construction of a 6-state, 6 symbol machine. As far as I know, this is the smallest known UTM. (In fact the counter machine described in the post was an ingredient in the construction)
Janos, thanks! I did consider adding that to Dick’s initial draft, and we may include it in a post sometime on how weak the definition of “universality” can be with regard to encodings of inputs and extraction of outputs from computations.
There are smaller UTMs since then, right? http://www.dna.caltech.edu/~woods/download/NearyWoodsMCU07.pdf and maybe https://en.wikipedia.org/wiki/Wolfram%27s_2-state_3-symbol_Turing_machine ?
Yes—but that’s where the issue of input and output encodings really comes in. Suppose you’re allowed to spend exp(t) steps in order to “mine” t-step TM computations M(x) (under standard encoding) out of some evolution, where maybe you also spent exp(|x|) steps to prepare “x” (in unary say). Does that help more “simple” evolutions become universal?
Minsky is credited with inventing the “useless box”. This box has a single switch on top. When the switch is pushed a finger emerges from the box, turns the switch off and then goes back into hiding. It’s all done with mechanical switches and a single reversible motor. I have one and it is surprisingly entertaining. This may not be his greatest intellectual result, but it’s probably one that will have the most impact generations to come.