Projections Can Be Tricky
Projections can be tricky

Henri Lebesgue is famous for the creation of modern measure theory. His definition of what we now call the Lebesgue Integral replaced previous notions of integrals. These were due to such great mathematicians as Isaac Newton, Gottfried Leibniz, Augustin-Louis Cauchy, and Bernhard Riemann. His definition was one of the landmark achievements of mathematics. His notion has many beautiful properties that all previous definitions lacked.
Today Ken and I wish to talk about the role that projections play in mathematics. And further how tricky the seemingly simple concept of projection can be.
The main reason we are interested in discussing projections is to raise points of comparison between these two developments:
- A classic result of Volker Strassen on lower bounds for arithmetic circuits. His result, even after 37 years, is the best known general lower bound on arithmetic computation.
- A recent claimed result of Vinay Deolalikar on Turing Machine lower bounds. His claim, if true, would be the best result ever on Turing lower bounds.
Both attacks need to face and handle issues that arise from projections. Strassen does this in a clever way that we will describe shortly in some detail. It is a beautiful argument. Deolalikar may or may not know how to handle projections. We will see. But, this issue of projections in his “proof” has emerged as the main conceptual gap in his proof strategy for 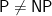
How hard can the notion of projection be? After all a projection is just the notion of a shadow—right? Well it can be very tricky. The great Lebesgue once made a “throw-away” remark about how sets behave under projections in a monograph. Here is a wonderful summary of the error:
Lebesgue in his preface (to Lusin’s book) humorously points out that the origin of the problems considered by Lusin lies in an error made by Lebesgue himself in his 1905 memoir on functions representable analytically. Lebesgue stated there that the projection of a Borel set is always a Borel set. Lusin and his colleague Souslin constructed an example showing that this statement was false, thus discovering a new domain of point sets, a domain which includes as a proper part the domain of Borel sets. Lebesgue expresses his joy that he was inspired to commit such a fruitful error.
Let’s now turn to discuss projections, and how Strassen handles them while perhaps Deolalikar does not. But, that a great mathematician like Lebesgue can be mistaken about projections should be a reminder to us all. The rest of this post is by Ken Regan.
Let’s Be Nice
Let us abbreviate Deolalikar’s key concept of “polylog parameterizability” of a distribution by the English word “nice.” Then the facts established by his paper, as summarized on the wiki page opened by Terence Tao, become:
- If
, then the solution space of any
-SAT problem with at least one solution supports a projection of a nice distribution.
- The hard phase of
Subsequent to Tao’s original comment on this, the paper’s public examiners have agreed that these two facts do not, and conceptually cannot, combine to make a proof of
Do your concepts stay nice under projections?
We will see how Strassen managed with a concept that stays nice, but then explore whether any strategy for better lower bounds can do so.
Projections
Consider your shadow cast by a broad light against a back wall which we will call the 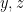


A point 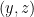
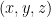
Now the point
To see why, first suppose 


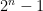



The analogy to Vinay Deolalikar’s paper can be made even better by considering just 

Shadows and Slices
The idea that your shadow can be more complex than you sounds laughable. If anything, features of your head get simplified. If you have a double chin, it’s gone. Your hair may now mask your ears. If people enter the room, their shadows may combine with yours. But you will never, ever, see more people in a shadow than you have in the room.
The abstract mathematical fact is that the number of connected components of an image can never increase under projections. This is so even under general kinds of projections that may be onto an arbitrary subspace, even an affine subspace meaning one not through the origin, or may be stereographic meaning from a pinpoint not broad source. It seems that anything “physical” or “statistical” about a structure should become simpler when you take a projection. Or at least it should not get more complex.
Projections should not be confused with slices. A slice is what you get by fixing a variable, or substituting an affine linear expression for a variable. If you fix a formula 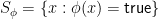
If you take a thin slice of a donut across the hole, you get two circular pieces. Thus it’s not a surprise that the complexity can go up with slices. In fact, you might start with a formula 
Slices can be used as supports of distributions. You can even take a section which is an adjacent set of slices. Further you can induce distributions on subsets of the global solution space
Volker’s Complexity Measure
Recall we talked about arithmetical formulas last week here. If you allow the 



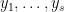
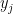
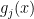


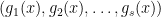
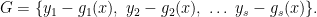
We are now ready to define Strassen’s measure. We have 
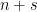

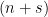


Theorem: Every arithmetic circuit
computing
must have size at least
.
Walter Baur later helped him extend this to lower-bound the circuit size of a single polynomial 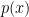

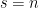

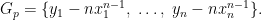
Make 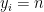

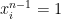

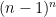
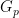
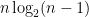
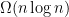

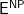
How the Measure Plays Nice
It is immediate that Strassen’s measure 

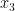
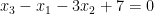
Non-increasing under projections is a little trickier, but boils down to what we said above about the number of connected components. There is no way to get more single points by taking a projection of the ultimate set
Consider a hypothetical circuit 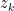
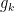
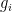
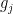


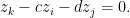
And if 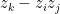
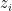

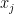
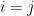

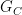
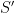
The graph of the mapping
Since every equation introduces a new variable, the full system 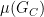
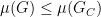
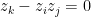
We have thus proved a lower bound on 
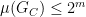

The Problem With Projections
The problem with the above observation about
The problem also shows up as a limitation on the measure 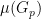
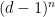
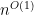

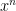
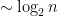
We speculate that these lacks may owe ultimately to the single fact that Strassen’s 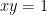
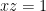
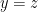
Ironically this puts Deolalikar’s “pp” complexity measure in the opposite situation from Strassen’s 
Endgame?
It remains to ask whether it can be modified in a way that sidesteps the problem like Strassen’s
Can a “statistical” property of distributions ever become more complex under projections?
If by “statistical” we mean purely numerical or physical properties encountered in everyday situations, the answer may seem to be “no,” as surmised by one of my colleagues in computer vision. However, two others postulated an example where a high-entropy distribution in a 2D plane masks a low-entropy one in the 3D interior. More crudely, one can picture a complex 2D pattern simply being replicated along the axis of projection.
A “no” answer would be great if Deolalikar’s “pp” measure were solely statistical. However, the measure’s definition involves the existence of an acyclic graph on which the numerical properties are mounted. This graph is very like the circuits
Open Problems
Can we hope to prove lower bounds with a complexity measure that is preserved under projections? Can we hope to prove lower bounds with a complexity measure that is not preserved under projections? What happens with slices?
Can the arithmetical
Can results over infinite fields lead work over discrete domains at all? Is this like, or unlike, the history of the Prime Number Theorem?
Trackbacks
- That bet on P vs NP « Pythonic Nature
- Top Posts — WordPress.com
- Mal wieder ein bisschen Wind um P und NP « Mathekram
- July Fourth Sale Of Ideas « Gödel’s Lost Letter and P=NP
- Grilling Quantum Circuits « Gödel’s Lost Letter and P=NP
- Definable subsets over (nonstandard) finite fields, and almost quantifier elimination « What’s new
- Alexander Grothendieck 1928–2014 | Gödel's Lost Letter and P=NP
- Open Problems That Might Be Easy | Gödel's Lost Letter and P=NP
- A Panel On P vs. NP | Gödel's Lost Letter and P=NP
- A Magic Madison Visit | Gödel's Lost Letter and P=NP
- Jean Bourgain 1954–2018 and Michael Atiyah 1929–2019 | Gödel's Lost Letter and P=NP
- The Shortest Path To The Abel Prize | Gödel's Lost Letter and P=NP


For some footnotes: A flip side of “projections” is “padding”, and this has affected key mathematical concepts of Ketan Mulmuley’s and Milind Sohoni’s /Geometric Complexity Theory/ (GCT) approach from the beginning. For a graphic illustration of the kind of embedding relation between structures associated to the permanent and determinant (respectively) that GCT seeks to show is impossible unless the permanent has high complexity [or rather, unless one uses very high “N” for the determinant], see slide 23 of
this presentation by Scott Aaronson.
I decided not to address the difference between string-valued and scalar-valued variables. With the former, or with appropriate decoding primitives, one can say that every r.e. language is a projection of a poly-time decidable predicate. Take it as implied than when the article moves to circuits as the basic model, it’s talking about a fixed polynomial number of extra scalar variables. This also could have led me to discuss compactness in the continuous-space domain, but this sort of thing can be done in comments…
Dear Kenneth, it would be very nice to have a full post on Mulmuley’s GCT approach (and its latest status) at sometime, addressing how it may or may not evade known barriers. As you have written a review on the approach some time ago, I guess this would be a perfect match! 🙂
Thanks, Martin—It’s a natural suggestion. May have to wait until end-September, however. In the meantime, let me refer people to Peter Bürgisser et al.’s survey a year ago, An overview of mathematical issues arising in the Geometric complexity theory approach to VP v.s. VNP.
Ah, my clause “Since every equation introduces a new variable…” leading off one paragraph should change “introduces” to “is set equal to”, or should append “…as a term to itself.” This can be relaxed, but that was the intent.
It might be worth mentioning that every set in NP arises as a projection of a set in P. (Given X in NP, the set Y = {(x,p(x)} consisting of members x of X each paired with a proof of membership of x in X is in P, and X is the projection of Y on its first coordinate.) Hence if projection were to preserve time complexity, even only to within a polynomial, P = NP would be an immediate consequence.
As a case in point, the set of all solvable Sudoku puzzles of a given shape and size having the same blank squares is the projection of the set of Sudoku solutions of that shape and size obtained by projecting out, or erasing, the blank squares in those puzzles. Projection is what makes Sudoku a challenge even though every solution is easily verified.
The computability counterpart of this is even stronger: a set is recursively enumerable if and only if it is the projection of a recursive set. This gives a slick characterization of the r.e. sets, namely as those sets arising as the projection of a recursive set.
Noting that the “if” direction of this connection is missing in the case of the first paragraph, it’s a nice exercise to work out the analogous characterization of NP in terms of P via projection. (Hint: first show that every r.e. set arises as the projection of a set in P.)
How fantastic! I enjoyed reading this reply.
Is there a nice notion of sparseness of a projection?
And if you wish to check your answers to the exercise, you may look here:
http://mathoverflow.net/questions/34832/correct-to-characterise-np-set-as-p-time-image-of-p-set
=)
The notion shown in the exercise (second answer) is called “polynomial honesty” in the literature. My “footnote” comment above seeks the same effect by insisting that variables be scalars [over some finite domain] and a fixed polynomial bound on how many coordinates get zapped.
Sparseness of a projection—hmmm, how to define that? I wonder if you mean something even tighter than linear honesty? If you mean that at most polylog(n) extra co-ordinates get removed, then [again, over a finite domain] you could try all combinations and still run in quasi-polynomial time. I would use it to mean o(n) extra coordinates—maybe O(n/log(n))—and then it does verge on things Dick and I have been thinking about…
The idea that your shadow can be more complex than you sounds laughable.
…unless you’re a geometer, I guess.
Make two fences, each out of n closely-spaced parallel sticks, like this: |||||||. Turn one of the fences 90 degrees so its n sticks are horizontal. Now make the planes of these two fences parallel. By any reasonable definition of “complexity”, this geometric object has complexity O(n). But with the light in the right direction, its shadow is an n×n grid, which has (again using any reasonable definition) complexity Ω(n²).
Less intuitively, with three fences made from straight sticks and an area light source, you can actually make curved shadows.
Similarly, arbitrarily smooth curves can have arbitrarily non-smooth shadows.
This is a loosely related question, that I would be grateful if anyone could give references to:
Let’s say we are sitting by a lake, surrounded by trees. Imagine the water surface to be a perfect reflection (i.e. no waves), and in the reflection you see the trees – they appear exactly as the trees we can see surrounding the lake, hence it is easy to imagine that the reflected tree corresponds to a real shape.
Now a small wave disturbes the surface and the reflection gets distorted. As the wave is small, we can somehow still imagine that if we didn’t know of the wave, the reflection actually corresponds to a real albeit ‘bent’ tree out there, fully possible to exist.
Finally, the waves get amplified and the reflection fails to be connected and we are not able to understand what kind of shape would correspond to the reflection that we see, if we are unaware of the surface being distorted.
My question is: is this a well defined mathematical problem, finding the maximum amplitude of the wave?
Also, is it possible (using PDEs?) to reconstruct the distorted object; that is actually finding the description of the ‘bent’ tree, given the real tree and the surface in which it is reflected? I assume that the wave has to be small for this to work?
Thanks in advance you for any answers or references.
Projections are notoriously tricky buggers in any type of problem. In algebraic geometry, projections correspond to *elimination*, a process so algorithmically painful that early 20th century mathematicians cheered when they found ways to bypass it.
Replying to JeffE then Random: My first reaction to your “fence” idea is that the same structure is present in both cases. However, in the 3D case it is sparse, and would register lower complexity than the 2D pattern in a measure that divides by volume (respectively, area). The entropy-based examples from my two vision colleagues seem to be analogous.
While writing the post I was trying to think of a smooth 3D curve with a non-smooth 2D projection, something “fractal” I was thinking, but I couldn’t. Still can’t find with a quick Google search after a long day, so I’d love to see an example.
Random, funny to hear you speak thus about elimination—after using the Gröbner-based software package called Singular for over a decade, it’s a natural algorithm for me. But even there, often my trials in an elimination order run for too many hours/days, so I try with a faster degree-based order to see if I can get enough idea of a possible solution to continue.
What I’m mainly after, however, is some theory on the behavior of polynomial ideals under substitutions, even “slices”. Identifying sets of variables or substituting constants is sometimes called a “Valiant projection”, and every formula is “projectable” that way from a read-once formula of the same size. The first partials of a read-once formula (and some more general cases) form a Gröbner basis. I had an attack based on identifying pairs of variables one-at-a-time, but in some experiments the Gröbner complexity mushroomed already after only a few such substitutions into a read-once formula, and there are counterexamples to the big-kahuna goal it had, so I abandoned it.
I had something very specific in mind when I wrote my post, but I couldn’t find the quote again. It was from Andre Weil’s Foundations of algebraic geometry, and it goes: “The device that follows, which, it may be hoped, finally eliminates from algebraic geometry the last traces of elimination theory […]”.
I first encountered that sentence in Abhyankar’s Historical Ramblings in Algebraic Geometry. Needless to say Abhyankar is less than impressed by this attitude, and of course computers have sparked a renewed interest in the subject (with algorithms that have substantially improved on Buchberger’s ideas). Still, there is no doubt that projections are not trivial (and the complexity gets worse over the reals!).
While writing the post I was trying to think of a smooth 3D curve with a non-smooth 2D projection
The image of the moment curve (t, t^2, t^3) is smooth. The image of its projection (t^2, t^3) into the yz-plane is not even differentiable at the origin.
This is a really nice analogy, thanks.
Though, I think that while the 3D example with the shadow of a person is great, a 2D version might be even easier to grasp and reason about.
(It might also help with vagueness about “solution spaces” – i.e. is the solution space a single column for a given x? the set of all columns? the projection over rows? what is on your axes – formulas/assignments, or instances/non-deterministic bits of a general NP problem? etc.)
In data mining and statistics, projections appear prominently. For example, the famous EM algorithm, is a sequence of projections on the manifold defined by the parameters of the probability distribution. In fact to estimate the parameters of a pdf f(x), it is often written as a sum (over z) of a another distribution g(x,z) which has a “nice” form.
Just found that Deolalikar’s paper is now available as a Technical Report on the website of HP Laboratories.
http://www.hpl.hp.com/techreports/2010/HPL-2010-95.html
Does anyone know if this is the latest version that was sent to journals and supposedly fixes the known bugs?
I want to expand on Sanjay Chawla’s post by observing that projections (and their natural generalization pullbacks) are ubiquitous nowadays in *every* STEM discipline … and I will further cite some references to the effect that the topic of projection-and-pullback is taught very poorly at the undergraduate level.
Hopefully students (especially) may have fun looking into some of these references …
A fun start is William L. Burke’s samizdat classic of applied mathematics, Div Grad and Curl Are Dead. Regrettably, Prof. Burke died in an accident before his book was published … fortunately it is available on-line (in a draft version).
In Burke’s “Chapter 0: Prolegomena” (page 7 of PDF) we read the following hilariously transgressive polemic:
——————————
I am going to include some basic facts on linear algebra, multilinear algebra, affine algebra, and multi-affine algebra. Actually I would rather call these linear geometry, etc., but I follow the historical use here.
You may have taken a course on linear algebra. This to repair the omissions of such a course, which now is typically only a course on matrix manipulation.
The necessity for this has only slowly dawned on me, as the result of email with local mathematicians along the lines of:
Mathematician: When do you guys (scientists and engineers) treat dual spaces in linear algebra?
Scientist: We don’t.
Mathematician: What! How can that be?
——————————
Some other texts that take an enjoyably “Burkean” attitude toward projection and pullback are Feynman’s 1961 Quantum Electrodynamics, Arnold’s 1978 Mathematical Methods of Classical Mechanics, Troy Schilling’s 1996 thesis Geometry of Quantum Mechanics … and worthy of special mention (IMHO) is John Lee’s 2003 Introduction to Smooth Manifolds; this is IMHO a wonderful text (it is known to grad students as “smooth introduction to manifolds”).
These works all teach a mathematically natural view of dynamics in general—and projection-and-pullback in particular—that is very much in the spirit of Dick’s previous theme “Mathematics That Teaches Us Why” … this “teach us why” spirit represents (one can hope) an exceptionally fruitful organizing principle for 21st century STEM education.
The preceding is why (for us engineers) a particularly novel and fruitful aspect of Ken and Dick’s discussion of projection, is its emphasis that “Projections Can Be Informatically Tricky.” This informatic theme is not developed in any of the preceding textbooks, or in any other textbook on dynamics that I know. Ken and Dick’s post amounts to a compelling argument that students benefit greatly from appreciating “projective trickiness” in all its aspects … and that Vinay Deolalikar’s manuscript in particular might have benefitted from a great appreciation of it.
So it seems (to me) there are some terrific “projective” opportunities here both in STEM research, teaching, and practical applications. It’s this three-fold impact that (for me) makes the general topic of “projective trickiness” especially interesting.
This reminds me of when I took Linear Algebra in college, and it was all about linear transformations on vector spaces, null spaces, norms, various decompositions into subspaces, and Jordan and Rational Canonical Forms, and the like.
Now in the middle of the course, I came across an old book from the 1950’s in the library, which was titled “Matrix Algebra.” In it was everything from my Linear Algebra course, but with nary a mention of vector spaces or linear transformations. It was all about MxN matrices of numbers.
So I went back to the professor, who was somewhat of a renowned algebraist, and asked, “Why introduce the unnecessary abstractions of vector spaces and linear transformations, when everything we’re doing can be done using only ordinary arithmetic on numeric matrices?”
He replied, “Because people who think of Linear Algebra in terms of vector spaces and linear transformations do more interesting things than people who think of Linear Algebra in terms of arithmetic on matrices of numbers.”
Just to show things come full circle, a friend of mine who recently completed a BS in Physics took Linear Algebra, and his course was all examples of matrix arithmetic using Matlab, with nary a mention of vector spaces, linear transformations, or anything abstractly mathematical.
Fnord, all that you say about algebra, applies with redoubled force to geometry and to dynamics (and many other mathematical disciplines too).
It is a shocking fact that nowadays students can earn an undergraduate degree in almost any STEM discipline without ever having been exposed—in even one lecture or textbook—to even such a fundamental notion as mathematical “naturality”.
Although these graduating students will have learned many mathematical facts, only a few of them will have been so fortunate as to discover spontaneously that (in Bill Thurston’s words) “Mathematics is an art of human understanding [that] we feel with our whole brain.”
Thurston’s mathematical-yet-human understanding is increasingly central to all forms of creative and synthetic activity within the STEM community … it is necessary therefore that we find better ways to communicate it … otherwise we will neither grasp the wonderful opportunities of the 21st century, nor meet its urgent challenges … and accounts for a large measure of my interest in this and other STEM blogs.
For which, my thanks and appreciation are extended to Ken and Dick, for extending (yet again) at least one reader’s notions of mathematical-yet-human naturality.
Thanks also for the appreciation—and e-mail too. Your use of “natural” may be aligning with the intent of Razborov and Rudich in using that word, in hinting that the kind of “nice” math we cognitively “grok” might be powerless on circuit lower bounds.
This also gives me a pretext to mention something I cut from the article. Einstein’s quote “Raffiniert ist der Herrgott, aber boshaft ist er nicht” has been given quasi-religious meaning (“Subtle is the Lord…”), but I think it was only speaking to a difference between physics and pure-math research. He clarified it to Oswald Veblen as: “Die Natur verbirgt ihr Geheimnis durch die Erhabenheit ihres Wesens, aber nicht durch List”, which I render non-standardly as “Nature hides her secrets as the perquisite of lofty birth, but not through mean trickery.” That is to say, in physics—and especially in a geometric theory like relativity—your intuition will not be wantonly deceived. If it is looking high enough, it will succeed, even if it must get by singularities. In math, however, it seems that even on fundamental grounds alone, any nastiness that can occur, mustoccur—somewhere saliently. Certainly if one works in the Riemann Hypothesis, where so many things can be true of the first quadrillion or so integers and then turn south, one must be prepared for “All Boshaft, All The Time.” The “barriers” in computational complexity often feel the same…
I thought this was an excellent and provocative post. It took me back to thinking about projective (and injective) modules and the like, and started raising questions about the algebra of projections, and the implicit question “how does one choose a good projection” (Strassen managed).
I happen to be reading HSM Coxeter on Projective Geometry just now – and also the recent biography of Paul Dirac (The Strangest Man) – which suggests that his early ideas in Quantum Theory were in part built on his early training in, and ability to visualise and intuit within, projective geometry.
I am left pondering just how much mathematics can be conceived from a projective point of view.
Vaughan’s comment above shows how some particularly natural projections illuminate particular problems. I suppose that one question, from the projective side of things, would be whether there were other less obvious projections (orthogonal in some sense?) which would reveal more tractable elements of the structure.
Just thinking about this brings me back to Fourier Analysis and Quantum Computing …
Stephen Cook finally had his revenge on American academia …
http://en.wikipedia.org/wiki/Stephen_Cook#Biography
But he had to sacrifice his own reputation for it.
This question came up in the earlier discussion of the “proof”. I did not find the responses satisfactory. Let me state it more clearly.
Let A consist of the following data: a Turing machine algorithm accepting bit strings, and a polynomial time bound (absolute – i.e., not asymptotic). We define n(A) to be the least length of a bit string x such that when the Turing machine algorithm runs at input x for the number of steps given by the time bound declared in A (as a function of the length of x), the resulting computation witnesses that A is not an algorithm for SAT. I.e., either A encodes a tautology and the algorithm does not return “yes” within the time bound declared in A, or A does not encode a tautology and the algorithm does not return “no” within the time bound declared in A.
If P != NP is provable in a weak formal system, then we do get an upper bound on n(A) as a function of the size of A. Roughly speaking, the weaker the formal system, the better this upper bound is. This is at least implicit in the literature.
However, if we merely know that P != NP, then can we get any upper bound on n(A) at all? I was thinking “no”, but perhaps I am missing something important here.
(I assume you mean “x encodes a tautology” instead of “A encodes a tautology”.)
My guess is that there is no “compactness” property we know of that prevents NP from being “arbitrarily close” to P, e.g. there might exist an algorithm that solves (say) 3-SAT in time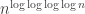 , and this is essentially best possible. (Of course, one could consider far slower growth functions here than
, and this is essentially best possible. (Of course, one could consider far slower growth functions here than 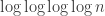 , e.g. inverse Ackermann.) With this intuition, I would say that n(A) could (in principle) grow arbitrarily fast in A.
, e.g. inverse Ackermann.) With this intuition, I would say that n(A) could (in principle) grow arbitrarily fast in A.
One could possibly bound n(A) by some sort of Busy Beaver function, but that would probably require P!=NP to not just be true, but to be provable in a specific formal system. But this is something you are more qualified to discuss than I. 🙂
Terry wrote
“(I assume you mean”x encodes a tautology” instead of “A encodes a tautology”.)”
Yes, thanks for pointing out my typo!
If P != NP is true then n(A) is a recursive function of A, by search, and so is automatically eventually bounded by any of the usual Busy Beaver functions (see http://en.wikipedia.org/wiki/Busy_beaver).
It is interesting to look into the relationship between running times for solving 3-SAT and the function n(A) in my previous message.
I don’t have the patience right now for this sort of tedious stuff, but the following should be reasonably close to the truth:
THEOREM. 3-SAT can be solved in running time at most n^(c^(f^-1(n))). If 3-SAT can be solved in running time at most n^g(n) then g(n) >= log_c(f^-1(n)). Here f is the function n(A) in my previous message.
Proof: Let x be a problem instance of length n. Let m be greatest such that f(m) <= n. Then there exists an algorithm y of length at most m that solves 3-SAT for all problem instances of length at most n running in time at most (2^m)(n^(2^m)). But at this point we don't know what y to choose. So we go through the y of length at most m, running them, and see if a falsifying assignment is generated in the obvious way. If so, then return yes for x. If not, then return no for x.
Suppose 3-SAT can be solved in running time at most n^g(n). Etcetera… QED
To contrast P != NP with the Riemann hypothesis, in the case of the latter there is a quantifiable (but ineffective!) gap between the bounds in the error term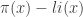 in the prime number theorem in the case when RH is true, and when RH is false. Namely, the error term is
in the prime number theorem in the case when RH is true, and when RH is false. Namely, the error term is 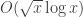 when RH is true (and there is even an explicit value for the constant, namely
when RH is true (and there is even an explicit value for the constant, namely 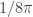 for
for 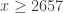 ), but will be larger than
), but will be larger than  infinitely often for some
infinitely often for some 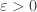 if RH fails (indeed, one takes
if RH fails (indeed, one takes 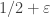 to be the real part of a zero to the right of the critical line). This comes easily from the “explicit formula” linking the error term in the prime number theorem to the zeroes of the zeta function (roughly speaking, the error term is something like
to be the real part of a zero to the right of the critical line). This comes easily from the “explicit formula” linking the error term in the prime number theorem to the zeroes of the zeta function (roughly speaking, the error term is something like 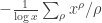 , where
, where  ranges over zeroes of the zeta function). But the bound is ineffective because we have no lower bound on
ranges over zeroes of the zeta function). But the bound is ineffective because we have no lower bound on  .
.
This gap between bounds when RH is true and RH is false can be used, among other things, to phrase RH in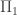 in the arithmetic hierarchy (as Dick pointed out some time ago on this blog).
in the arithmetic hierarchy (as Dick pointed out some time ago on this blog).
For P != NP, there is nothing remotely resembling the explicit formula, and so we don’t have this gap in bounds; nor can we place P != NP or its negation in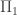 .
.
Dear Terry,
That’s exactly what I was getting at. That, at the moment, we should classify P != NP as being in Pi- 0-2 (Greek capital pi, superscript 0, subscript 2), which in terms of quantifiers is (forall)(therexists), or AE. Over the years, there seem to have been dozens of somewhat different estimates connected with the Riemann Hypothesis, showing that it is in Pi-0-1, as Terry writes.
This business of classifying open mathematical questions in terms of their logical complexity is something that has not been pursued in a proper systematic fashion. This can also be done reasonably robustly for solved mathematical questions. Here one has to address the objection that solved mathematical questions are either 0 = 0 or 1 = 0, and so in Pi-0-0, and there is nothing to do.
As a tangent to a tangent to the main points in my book at http://www.math.ohio-state.edu/%7Efriedman/manuscripts.html section 3, I endeavored to take all of the Hilbert problems and classify them in these terms.
See the Introduction only, and then only the section 0.3, E.g, Twin Prime is Pi-0-2, Goldbach is Pi-0-1, Collatz is Pi-0-2, and so forth.
I think I did at best only a passable job, and, given my limited research efforts in core mathematics, I could use plenty of help from mathematicians in various areas to make this tangent to a tangent much better.
In fact, when I wrote the Introduction, I had the ambition of doing the same for Smale’s Problem List, and for the Clay Problem List! To systematically treat a classification of this kind for these three problem sets, would itself take a large book.
Indeed projections are extremely important and mysterious. Regarding nice distributions it is not clear to me yet
1) which sets support projections of nice distributions. (Or, in other words which set are ppp). So it is not clear if the main missing piece in D’s argiment is equivalent or similar to NP=! P or amounts to something that is just plain false.
2) Also it was claimed that the ppp distributions were already consider before (under a different name) is there a definite word on that.
3) Regarding the claim that k-SAT does not suppport a pp distribution. Is this a proven fact? In D’s paper or elswhere
(As Paul Beame mentioned the old claims that NP=P were also based on projection arguments and this lead to interesting theorems by Yannakakis on why this approach must fail, at least under some symmetry conditions, and there are still related interesting questions regarding projections of polytopes.)
1) Sets that support ppp are precisely sets whose membership can be recognized with non-deterministic c^polylog size circuits (this is slightly larger than polynomial, since c^polylog contains some faster growing functions than polynomials); see this comment by Jun Tarui http://rjlipton.wordpress.com/2010/08/15/the-p%E2%89%A0np-proof-is-one-week-old/#comment-5863, here he takes polynomial size instead of c^polylog, but he is essentially right. As a special case, solution space of k-SAT formulas support ppp.
3) There was no proof of this in paper and I have not seen it elsewhere. Jun Tarui comments about this here http://rjlipton.wordpress.com/2010/08/15/the-p%E2%89%A0np-proof-is-one-week-old/#comment-5838
Some other solution spaces, like for XORSAT or EVEN, do not support pp distribution which was also proved by Jun Tarui in discussion/on wiki
k-SAT (or more generally, any non-empty solution space of an NP problem) supports ppp distributions (by starting with the uniform distribution on , and then returning some default solution if one falls outside the solution space). ppp supports seem to be close to something like a “polynomially computable image of a cube”, but I do not know the precise characterisation.
, and then returning some default solution if one falls outside the solution space). ppp supports seem to be close to something like a “polynomially computable image of a cube”, but I do not know the precise characterisation.
In order to support a pp distribution, the behaviour of the solution space in one of the variables (a terminal one in the pp factorisation) must depend on at most a polylog number of the other variables. Thus for instance the set EVEN of n-tuples (x_1,…,x_n) that add up to 0 mod 2 does not support pp, and more generally neither does a typical solution to a XORSAT problem. From the known clustering properties of SAT I can well believe that the same is also true for SAT in the hard phase, and it is likely that Deolalikar’s paper contained a proof of this fact.
I may not fully understand everything here, so forgive my ignorance but,
1. Polylog-parametrizations are only important because they constrain the size of the tables to represent conditional distributions.
If however you are allowed to use simple circuits to return parameters of a conditional distribution then the case EVEN of n-tuples (x_1,…,x_n) that add up to 0 mod 2 does support a pp distribution, where x_n’s conditional distribution is just a simple circuit that computes 0 mod 2 of the sum and returns either 0 or 1 depending on whether x_n has to be 0 or 1.
Of course this doesn’t appear to help anything because now you have to prove that no such similar circuit can characterize the conditional distributions of k-sat.
2. Knowing a solution a priori when constructing a distribution seems like a bit of a cheat, like using an oracle. If we banned such a construction would k-sat still be in ppp?
Since it was never clearly said in the paper what polylog parametrabizility means, it is not clear what is the missing part. If this means solution space does not support ppp, than this is false, since k-SAT formulas support ppp. However, if this means solution space supports a quasi-uniform distribution, than k-SAT formulas likely do not satisfy this, but this is no easier to prove than P!=NP. It is easy to see that we can sample quasi-uniform distributions on k-SAT0 formulas with polynomial algorithms if and only if P=NP, for instance. On the other hand, proof that k-SAT formulas do not support pp distributions is possibly not hard (similar things have been proved here for EVEN, n-XORSAT, n-SAT), but pp is useless in characterizing P, since very easy computable sets do not support pp (even {0,1}^n \setminus {(0,0…0)} does not support pp).
Hence, D.’s method and notion of parameters in any interpretation has no hope of giving anything useful.
After watching Inception, I agree projections can indeed be very tricky!
Is there some relationship with projective sets and projective determinacy? It seems like there ought to be.
Gil Kalia says: “Projections are extremely important and mysterious …”
Ken Regan says: “A flip side of projections is padding …”
And so, any engineer might reasonably conclude: “This is great! Surely,
MathSciNet will lead me to articles that discuss the interrelation of padding and projection.” But this reasonable conclusion would be wholly wrong … there are (to leading order) no such MathSciNet reviews.
It takes awhile for engineers even to guess that perhaps fine-grained padding is all about involutions and foliations (or is it?) and coarse-grained padding is all about complexity/cryptography (or is it?) … and that all of these concepts are broadly subsumed under the ubiquitous mathematical notions of pullback and pushforward (or are they?).
It is evident in any event that the unity of these subjects—projection-versus-padding, pullback-versus-pushforward, efficiency-versus-cryptography, foliation-versus-reduction, etc.—is more universally appreciated among mathematicians as individual practitioners, than it is reflected in the (present) mathematical literature.
That is why weblogs like this one are immensely helpful in helping to establish—for us engineers especially—that vital appreciation of mathematical naturality and narrative coherence, that is necessary to the practical application of mathematical advances to this century’s urgent problems (this is true also of Terry Tao’s well-integrated summary of the 2010 Field Medals).
In particular, Dick and Ken’s overview of projections, and the accompanying (terrific!) discussions, are substantially (albeit slowly) expanding our QSE Group’s conception of the mathematical roles of projection in STEM enterprises—both how to apply methods of projection and how to teach them—and for this our appreciation and thanks are (as always) extended.
The link gave by Anonymous above at time stamp (August 20, 2010 6:47 am) no longer works, even though the paper is still listed on the parent page. It appears the paper has been taken down again. 🙂