Lower Bounds and Progressive Algorithms
A new class of algorithms and an approach to lower bounds

Robert Floyd was an early leader of computational theory, who made especially important contributions to the design of algorithms. He became a Turing Award winner in 1978 for this seminal work, which revolutionized our understanding of algorithms. Perhaps his most famous paper is his 1967 paper Assigning Meanings to Programs. It alone has nearly two thousand citations.
Today I want to talk about how hard it is to understand programs, and the consequences that has for lower bounds. This applies to the recent claimed proof of P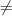
I knew Floyd, and had many conversations with him over the years. His Wikipedia article says
“His hobbies included backgammon and hiking.”
I think this is misleading. Hiking may have been a hobby, but backgammon was much more than a hobby to Bob.
We once were stuck at the Chicago O’Hare airport for hours, waiting for our flight to leave, owing to a snow storm. As we sat at our gate, Bob asked me, in a casual manner, “do you know how to play backgammon?” I answered I knew the rules, but why did he want to know? Bob said since we had several hours to wait perhaps we should play a few games, for small stakes of course. He then reached into his briefcase and removed a backgammon set.
My Dad taught me many things. One was to be wary of anyone who suggests a game of pool for money, and then opens a black case and starts to screw together a pool stick. I figured that this advice generalized to anyone who traveled with their own backgammon set. I told Bob that I was not going to play for money, no way. He pushed a bit, but finally said fine. He proceeded instead to give me a free lesson in the art and science of playing backgammon.
I was right to pass on playing him for money—at any stakes. The lesson was fun. I found out later that for years he had been working on learning the game. He took playing backgammon very seriously, studied the game and its mathematics, and was a near professional. I think it was more than a hobby. Like his research, Bob took what he did seriously, and it is completely consistent that he would be terrific at backgammon.
Let’s turn now to understanding programs and lower bounds, and how this links to Floyd’s work.
Alice and Bob Try To Understand Programs
Bob’s seminal paper, “Assigning Meanings to Programs,” showed how, in principle, one could understand a program. His ideas, which are now a standard part of computer science, were to attach assertions to the program. These assertions then could be proved, and this would yield a proof that the program worked as claimed. This was a brilliant insight—perhaps more so since it seems so natural and simple today. But he did it over forty years ago.
The trouble with this insight is the following, which I will show using our friends Alice and Bob. Suppose Bob has a program that he has created. Perhaps it is a beautiful new algorithm for matrix product, or an algorithms for some other neat problem. Bob wants to convince Alice that his program works. One method would be to use the technology created by Floyd. Bob could add assertions to his program, and then walk Alice through a proof that the program solves the problem as he claims it does.
So far all sounds good. But, let’s change the situation a bit. Now Bob wants to give Alice his program, but he does not want her to be able to figure out how it works. In this case Alice has to figure out what Bob’s program does on her own. She knows what it is supposed to compute, but she has no idea how it is doing the computation. This is a much harder problem for Alice.
I claim that this is the crux of why proofs of lower bounds that try to analyze the behavior of programs are hard, or perhaps even impossible. Over the years we have seen a number of attempts at lower bounds—not just for P
Progressive Algorithms
I have thought about this issue of understanding programs, and the relationship it has to lower bound attempts. I have an initial idea of how to formalize the difficulty that Alice faces when she tries to understand Bob’s program.
Before I give a formal definition let me try to give the intuition behind the notion that I suggest we call progressive. Suppose Bob claims that he has a program that determines whether or not a graph has a 
- Alice might assert that as Bob’s program runs it must make progress toward the goal of checking all possible sets of vertices to see if they form a clique.
- Alice then could argue there are lots of such sets of vertices, and this dooms the performance of Bob’s program.
This is a reasonable idea—I wanted to say “natural” but the above aligns only partially with the established meaning of that word in lower-bound proofs. Many algorithms do make progress in incremental steps. But, not all do this. Even the simple clique problem fails: For the case of triangle detection with 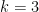
A Formal Definition of Progressive
Here is an attempt at a formal definition of progressive. Let’s work with boolean circuits, but I think the ideas can be adapted to almost any computational model.
Consider a correlation measure 



Suppose that

is a boolean computation for the function 



The value 


The intuition is that if 

Ken Regan has suggested how to make the definition more comprehensive this way: Let us introduce a “referee” 

Above we have the 
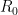
Note that we can regard the inputs 




Conjectures About Progressive Computations
I have two separate conjectures about progressive algorithms. They are stated for the simple referee but can be extended to others.
Conjecture A: Suppose that
is a boolean function with a circuit
of size
. Then, for any
, there is another circuit
of size
that is polynomial in
that computes
is its
step, then for


-clique problem on
vertex graphs. Assume for all
,
where
is a constant. Then,
where
tends to infinity.

Conjecture A states that we can modify any computation so that it appears not to be making progress toward its goal, and that this property does not increase the computational cost too much. For those who wish to prove lower bounds this should be a worry. It says that computations can be very complex.
Conjecture B states that computations that do make progress, in our formal sense, can have provable lower bounds.
Of the two conjectures I believe that it should be possible to prove A, using known cryptography technology. I actually think it should be provable with much stronger notions of “progressive.” We should be able to show that even the values of many of the earlier steps of the computation do not yield much quickly-digested information about the final answer.
The second conjecture I think needs new ideas to be proved. My intuition is that if the information of each step correlates better and better with the final output, this should severely restrict the computation. This may be strong enough to prove nontrivial lower bounds.
Open Problems
Is this definition a reasonable one? Does it capture the intuitive notion of an algorithm working toward its goal? Can we answer the conjectures?
A final question is: can we prove that many actual algorithms are progressive? I would conjecture that many “real” algorithms are progressive—either in the exact sense defined here, or in some small variation.
Trackbacks
- An Important Announcement « Gödel’s Lost Letter and P=NP
- Progress On Progressive Algorithms « Gödel’s Lost Letter and P=NP
- Let’s Mention Foundations | Gödel's Lost Letter and P=NP
- How Joe Traub Beat the Street | Gödel's Lost Letter and P=NP
- Working Backward | Gödel's Lost Letter and P=NP
- Lost in Complexity | Gödel's Lost Letter and P=NP
- Quantum Supremacy At Last? | Gödel's Lost Letter and P=NP
- Our Thoughts on P=NP | Gödel's Lost Letter and P=NP


i think that more work needs to go toward restricting the referee, and that this step might not be as easy as has been suggested.
aside from that, i like the conjectures. in particular, i think that for conjecture #1 you should be able to make the bulk of the action happen in the last O(log(t)) steps (maybe even fewer, but i am not sure how to do that).
There is a nice idea of Razborov that you don’t mention that almost seems to deal with progress notions such as the ones in Conjecture A but does not quite because you combine all partial results after each sequential step: Given a function f, one can write f as (f XOR r) XOR r where r is a randomly chosen function uncorrelated with f. Now g=f XOR r is also a random function uncorrelated with f. If you assume that g is computed first and then r, the algorithm itself will spend half its steps making no progress by your measure but in the second part of the computation it might slowly get closer to f by combining with the partial results from the first half.
This idea is also connected to the notion of a “progress measure” mu on Boolean circuits considered by Razborov and Rudich. Namely, they suppose that one has a measure that is sub-additive wrt OR and AND and small for the inputs and their negations then one can always has a natural proof (in their sense). The key difference with your progress measure is that it is proximity to f rather than absolute complexity.
Can this be recursed with a function g_1 that starts halfway through the computation so that 3/4 of the way through the terms start to collide and cancel? If this is the case, there might be a generalization such that introducing g_2, g_3, …, g_logn forces only the last few O(logn) steps to show progress.
Indeed (Paul and Ross), these are ideas we have in mind while trying to make this work. The “referee” formalism is intended to avoid what Dick calls the “bait-and-switch” problem. I/we are trying to revive some ideas I had some years ago that connected this to some cryptography-in-NC^0 papers. The hope is to catch the bait-and-switcher in-the-act using the ability to combine earlier partial results as you say.
I actually had Razborov’s modular-mu idea in mind while writing the projections post, to see if I could make an analogy to the “sub-multiplicative” nature of Strassen’s measure—but the post got long enough already. Interesting to explore it as a general issue in this context, so thanks!
A non-baked idea about Conjecture A: using “homomorphic encryption” we can make the computation “private” and the progress unrecognizable to the referee. We can build a program that gets an encrypted circuit and an input and simulates the circuit on the input without knowing what is being computed.
I’m trying to understand the notion of the correlation measure in the context of boolean circuits. I don’t understand what the notation f_1(x), f_2(x), …, f_t(x)=f(x) means. In particular, I don’t understand what do the functions f_i(x) represent. Clarification on that would be greatly appreciated. Thanks!
Sid,
Sorry. A boolean computation can be viewed as computing a series of functions. Each f_i is computed from some earlier function. At each step a boolean operation is done: NOt, AND, OR.
Indeed, there’s a change of viewpoint here from a Boolean circuit to a “straight-line program” (SLP) that’s sometimes surprisingly useful. If you have a circuit, number the inputs 1…n, then assign n+1 to a gate both of whose wires come from inputs (could be the same input twice, which makes more sense with arithmetic rather than Boolean circuits). Then always assign the next number j to a gate whose inputs already have numbers. Then each gate j is like a program line
j: f_j = f_i OP f_h
where f_i and f_h are the values computed at the earlier lines i: and h:. Here OP is the Boolean operation of the gate, and the value is just a bit. This view makes it clearer how each line j computes a function f_j. It also emphasizes that the program has no loops, which is part of the meaning of SLP.
We also pulled a notation shortcut with “R”—as worded it’s a “multi-ary function” like in C++ or Perl etc. So we technically need to say that R is a family of related simple functions R_j, where each R_j has j inputs. To apply “\rho” we need an n-input function g of x, so what we really have is
\rho(j) = \rho(g_j,f) where g_j(x) = R_j(f_1(x),…,f_j(x)).
We didn’t want to load up the post with the extra “g_j” and “R_j” notation, but if you wish to take it technically further, that’s the way to go.
A non-baked intuition about Conjecture B: the relation between progressive computation and increase in $\rho$ is one-sided, i.e. a computation may look like a progressive computation based on $\rho$ but may actually be carrying out a non-progressive computation and therefore we can’t say anything more than what we can in the non-progressive case.
Broder and Stolfi took this into another direction with their work on Pessimal Algorithms. Bob should be able to convince Alice that each line of his algorithm is making progress towards a solution, but Bob will be paid by the hour (or by the hours his algorithm takes).
Maybe not a serious consideration, but how I loathe Alice and Bob! Haven’t they got better to do in life than play these silly games for mathematicians’ content!
And their relationship! So eerily asexual, yet unsettling… brrrr.
This post *greatly* improved my appreciation of the intimate relation between proving lower bounds (hard) and validating algorithms (also hard) … for which my thanks and an appreciation are extended (as usual on this fine weblog).
Here is what our QSE Group calls “a confection”, namely, a pointer to work that surely is fun … and that *might* have a serious point to it.
To set the stage, let’s reflect “If only we knew God’s number … the number of steps that God’s algorithm uses to solve some nontrivial problem.” Well, we needn’t wonder for very long … a Google search for “God’s number is 20” takes us to “www.cube20.org” where 20 is the lower-bound (and as now has been proved, the upper-bound too) of turns needed to solve Rubik’s Cube.
What does God’s algorithm for Rubik’s Cube suggest to us about Conjectures A and B? For sure, it suggests that Dick’s “Conjecture A” is correct. To appreciate this, we need only watch the video at the bottom of the cube20 website … the video that is labeled “the hardest position for our programs.”
This particular starting position is the hardest of 43,252,003,274,489,856,00 starting positions, and so our intuition is that it ought to be mighty hard to solve! And indeed, for the first 14 moves there is no obvious progress toward a solution … then at move 15 faint traces of order are apparent … and finally, the last five moves solve the problem with a *bang*!
As far as anyone knows, this is how God solves most problems … she devotes most of her effort to preconditioning the problem … it is only the concluding stages of her algorithm(s) that are simple enough for mere mortals to understand.
This relates to several recent posts by Dick and Ken (Regan) … including in particular Dick’s (promised) discussion of Harrow/Hassidim/Lloyd quantum linear solvers (to which I am looking forward eagerly!)
For us mortals, the hardest aspect of solving a classical linear system is either finding a sparse, factored, or preconditioned representation of the system … or else (what is by far the hardest) proving that the problem at-hand has no such representation. It commonly happens too, that validating a claimed algorithm and/or verifying its claimed solutions requires more computational resources than computing the solution in the first place.
And finally, it is almost always the case (in practice) that the preconditioning/factoring/sparsification stage of solving a large linear system is the most mysterious and hardest-to-design stage … and also the single most important stage in terms of overall gains in efficiency. That is why preconditioning and factoring algorithms often are held as trade secrets, rather than being published in the open literature.
These problems are immensely challenging (and fun!) for even for classical linear solvers, and so they are likely to prove even more challenging (and more fun!) for as the STEM community begins to design quantum linear solvers.
It is fun, for example, to contemplate the mysteries of homomorphic encryption side-by-side with the mysteries of preconditioning. Hmmmm … could these mysteries be opposite sides of the same TCS coin? Is there a class of problems for which preconditioning accomplishes the same informatic purpose as homomorphic encryption … in the sense that the fast final stage of the computation is feasible for only those mortals who know the basis vectors of the preconditioning algorithm? Whereas everyone else can watch the (public) preconditioning without the least idea what end-stage computation is being preconditioned?
If so, then vendors of homomorphic data storage perhaps could compete in promising gains in algorithmic efficiency … which would be fun indeed!
John, you comment on a lot of the websites I silently lurk. Here you extend a thank you to Richard Lipton and Ken Regan for their wonderful post (it was indeed wonderful). But you yourself deserve a thanks for your consistently wonderful and insightful comments, not just here but also most every other blog. Specifically, in this post, I was wowed by the perspective described in the paragraphs surrounding “It commonly happens too, that validating a claimed algorithm and/or verifying its claimed solutions requires more computational resources than computing the solution in the first place.”
I second that opinion :-). We have communicated in private too—indeed I owe John a reply.
Thank you Ross. Without wishing to disillusion you … the ideas in my posts almost invariably can be found somewhere in the STEM literature—that’s why my posts contain so often give references.
Fortunately, today’s torrent of STEM literature is so broad, deep, and rapid that there are always plenty of fresh ideas to be fished from it (this is a tremendous advantage that the 21st century has over all previous centuries).
As for historical, philosophical, and literary ideas … well … if an idea in this class cannot be found somewhere in Lemony Snicket, then almost certainly you won’t find it in any of my posts either. So you might as well save time by reading some Lemony Snicket yourself … either to your own kids or to kids that you’re babysitting (if you need an excuse).
As for foolish, dull, and shortsighted ideas … now those ideas are being saved against the day I start my own weblog … which (with luck) will surpass anything ever before seen along those lines. 🙂
Ross,
Thanks for thanking and so on
Prof. Ken Regan’s comments on some of the posts on this blog suggest that the post is joint work of Prof. Lipton and himself. However, the post itself does not give that impression. Could Prof. Lipton clarify?
The post says “Ken Regan has suggested” [the referee formalism], and that’s what I’ve mainly been talking about. All the other paragraphs are by Dick, with some editing passes by me and Subruk. This post, like some but not most others, is touching on joint research plans we have.
http://blog.computationalcomplexity.org/2010/08/comments.html?showComment=1283098834016#c6959884731315934137
Comment. 41
Thank you for this enlightening article!
I am not sure what exact restrictions are imposed on the correlation measure, but assuming it is a simple distance function on boolean functions, the first conjecture is limited by the fact that for every Circuit C, there is SOME correlation measure d_C intimitely related to C where C DOES make progress: d_C checks whether its inputs reflect gates f_i, f_j of C. If so, it returns |i – j|. Otherwise it returns zero or infinity (or t+1 if you prefer) depending on whether its inputs are identical or not.
Thanks for that very nice story about Bob Floyd. On Wikipedia, some anonymous contributer had already reworded the backgammon bit (no doubt thanks to this post), and I reworded it again; it now reads “he was an avid backgammon player”. Your story, however, paints a more vivid picture. Would you give your permission to quote the text about your delay at the airport, from “We once were stuck (…)” to “(…) terrific at backgammon.”?
Trying to appreciate the complementary relation between Conjecture A and Conjecture B leads to a (well-written) Wikipedia article on the clique problem … which in turn describes a natural connection to hardness of approximation … which in turn leads to probabilistic proof-checking … which is discussed today’ on Tim Gowers’ weblog under the topic ICM2010 — Avila, Dinur, plenary lectures … which finally (via links that Tim provides) leads to Irit Dinur’s proof of the PCP theorem by gap amplification.
So it is pretty clear that Ken and Dick have structured their Conjecture A and Conjecture B to be both intuitively plausible, and and to have a rich set of tools available for attacking them. Students take heed … these two conjectures are a good example of how hard problems can be made more fun by structuring them so that they can be tackled with proof technologies that are known to be powerful.
I guess I’m confused about a very basic issue. Why would we expect the optimal k-clique algorithm (whatever it is) to appear to make progress for any particular correlation measure? Maybe it doesn’t make progress until the very end. So how does conjecture B prove anything about lower bounds on k-clique?
What are the limits on making an algorithm a progressive algorithm? Can any be made into one? Or is there some features an algorithm must have such that one could automatically make it progressive?
I wish I had something intelligent to say about these two conjectures, but for now all I’ll say is that I find them very interesting and appealing.
How about a more “optimistic” conjecture A’ – for every straight-line program, there exists a (not much slower) progressive one? Is this obviously false? If it were true, it would suffice to rule out progressive algorithms to prove lower bounds.
I think there is a very boring sense in which it is obviously true, but it may be possible to formulate the question in a way that invalidates this answer. At least according to the definition given in the post, if you took a non-progressive algorithm of m steps and then added a further m steps that applied identity gates to the output (or if you don’t like identity gates, then either m or m+1 not gates), then, strictly speaking, you will have converted your non-progressive algorithm into a progressive one.
This is just a simple example of many stupid tricks one could use, and I don’t immediately see a formulation of your question that rules out all of them.
Thanks for perceptive comment—and as I neglected to say earlier, this is a kind-of “flip-side” to Ross Snider’s comment above: You could be lucky to compute f(x) with n-1 gates (or log(n) levels if you take the circuit level-by-level) and then just have f,f,f,f,f,…,f,f,f all the way through. Or repeat something close to f.
We would wish to avoid this without introducing a notion of “minimal progressive”, but maybe we need it. In general we’re finding it harder to define “progressive” than “not progressive”, and we’re starting from piecemeal conditions from natural cases: If program P does X then it’s progressive; if it does Y then it’s not progressive.
The current attempt at an exact definition of “progressive”—assuming a correlation measure \rho(j) has been established—looks like this: Define the “progressiveness” of a circuit C of t gates as the minimum e such that for all j,
rho(j) is at least ((t – j)/t)^e
Lower e means more not less progressive (a linguistic issue we need to fix too). This still doesn’t solve your issue, but we can either impose some idea of “minimal” on t, or we can re-define the denominator “t” to be “t_opt” for an optimal circuit. Not sure which, and as you warn there are other pitfalls—which is why we’re first trying to flesh out what pre-conditions “X” and “Y” we really want.
Oops beg-pardon, the formula should just have j not t-j, i.e.
as j runs from 0 to t timesteps. Note also that for “t_opt” in place of the denominator, this can hold only for j below t_opt, since rho(j) maxes out at 1. Hence to meet your issue, either one narrows the range of j, or one is locked into only optimal circuits being progressive anyway. It’s hard to make this both robust and simple…
A less-immediate point of detail: As e goes from 1 to infinity, the floor for rho(t) goes from the line y = x/t toward the step function with a sudden jump at t. My intuition is more that the progression floors should be sigmoids, but I don’t know as nice a way to represent them with one parameter.
Formula is (left out a zero in the unfortunately-required background specification):
“The “referee” formalism is intended to avoid what Dick calls the “bait-and-switch” problem.”
I’d like to ask a question of both Dick and Ken. I’ve looked at Dick’s very interesting post on the bait-and-switch idea, and it relates to some things I was trying to do in relation to Conjecture A. But I run up against a difficulty that seems to apply to bait and switch too. Suppose we are interested in f and that r is a random polynomial-time computable function. Dick suggests (that Rudich suggests) that we should calculate the XOR of f and r and also calculate r, and finally XOR them together, in order to obtain a computation where no intermediate step correlates with the final answer. But the presupposition there seems to be that there is some entirely separate algorithm for calculating f \oplus r, since if we calculate f and then r and then XOR the two together we’ll have an intermediate step that correlates perfectly with f.
It might seem as though f\oplus r is basically a random polynomial-time computable function, but I’m not sure I quite see that: if both f and r take m steps, then f\oplus r is certainly not uniformly distributed amongst all 2m-step-computable functions.
This makes me wonder if there’s some point about the bait-and-switch idea that I haven’t yet grasped — I’d be grateful for any guidance.
A “simplistic” example of my remark which may connect to what you are saying is to consider a two-input function f'(x,y) that outputs f(x), where |x| = |y| = n. Let’s think of circuits C computing f that have n-bit levels, so C(x) has level-values v_1,v_2,v_3,…,v_t and from v_t one gets f(x) quickly. Taking v_j as functions, let’s even suppose rho(v_j,f) –> 1 nicely by Dick’s definition.
Now we make the circuit C’ where C'(x,y) has level-values w_j(x) = v_j(x) \oplus y. Now rho(w_j,f) does not progress nicely. However, we can introduce a referee R that can inspect the level-values w_j and the “y” part of the input and compute w_j \oplus y. With this R, we recover the original degree of progression. The point here relating to yours may be at least the computation of f(x)\oplus r is brought inside rather than being separate.
Where it gets less simple is if we consider more-subtle ways to have circuits C alter their values, and try to make a flexible class of referees R. Since I was thinking in terms of functions from n bits to n bits, my first thought was NC^0 for the referee class. Vector-XOR is just one example of an NC^0 function, and as we saw with w_j XOR y, it is its own inverse. The problem is that NC^0 is strong enough to do some kinds of cryptography—in fact, in a sense by Applebaum-Ishai-Kushilevitz it can “inherit” cryptography as high as parity-logspace. (See also a recent paper by Cook-Etesami-Miller-Trevisan; I’m not linking so as to avoid the mod queue.) So if R is disallowed from seeing an initial NC^0 level of C that does this encryption we may be in trouble, but if R can see the whole circuit maybe it can “catch the encryption in the act.” Whether to allow R (or rho) to see the input is the first issue Dick and I hemmed-and-hawed on—because e.g. some lower-bound proofs for “online” algorithms we would like to extend rely on having an adversary able to change part of the input consistent with choices so far.
Below I am putting a rough-intuitively-worded summary of both Dick’s post on “bait-and-switch” and its companion (featuring Razborov) on Natural Proofs. Ultimately we are hoping to avoid this by proving lower bounds against a class of programs that is hopefully tilting neither at strawmen nor at windmills, but the kind of statue that’s meaningful to knock over…
To illustrate the way “bait-and-switch” is regarded as a lower-bound obstacle, let me first be rough/intuitive. A lower-bound proof involves a notion of Easy and a notion of Hard. The horns-of-dilemma question one faces is:
Is a random function r Hard or Easy?
1. If you say r is Hard, then the “Natural” problem is that Easy can create a pseudo-random function f which will trick you into saying f is Hard (at least if your condition for Hard is single-exp(n)-time decidable).
2. If you say r is Easy, then let f be the function you’re trying to prove is Hard. Since f+r is also a random function, by all you can tell it is Easy. Now you’re in the situation of saying that an Easy op of two Easy functions can be suddenly Hard. This rules out the lower-bound strategy of showing that Easy op Easy = almost-as-easy. (And at least in the Boolean-op case of this strategy, Razborov’s “modular” argument given in Dick’s “Who’s Afraid of Natural Proofs” post throws you against the obstacle in 1. anyway.)
Now for an example of 2. which I tried to chase. My basic observation is that the Jacobian ideals of the determinant polynomials have no monomials in them (in fact, the (n-1)x(n-1) minors form a Groebner basis under any diagonal order.), whereas those for the permanent polynomials have many, specifically many m where no proper divisor of m belongs to the ideal. I still think this is a key structural difference between the two. So I have:
#m(Jac f) = 0 –> f is Easy
#m(Jac f) = Big –> f is Hard.
(Big can be ~ d^{2^n} for f of degree-d in n vars, with no obvious single-exp(n) way to decide this property of f.)
Now with generic as a stand-in for “random”, a generic polynomial r is Easy. Insofar as Perm – r is generic, it too is Easy. So any strategy of showing Easy op Easy = not-Hard is frustrated by the bait-and-switch of (Perm – r) + r = Perm. (Well, in this case worse: there are linear-size arithmetical circuits of total degree 6 that compute an f with #m(Jac f) = 2^{2^k} with k = Theta(n), so my notion of “Hard” isn’t. Insofar as Dick compares bait-and-switch to a con-man, this counterexample is like the jail sentence that follows—though I still seek ideas for a get-out-of-jail card.)